Solution for Azure Storage and Application Redundancy
AZ-304 exam is retired. AZ-305 replacement is available.
In this tutorial, we will understand the Azure Storage redundancy for replicating data including building application redundancy for avoiding single points failure.
Azure Storage Redundancy
Azure Storage stores multiple copies of data for protecting it from both planned and unplanned events such as transient hardware failures, network or power outages, and massive natural disasters. In this, redundancy ensures that your storage account meets the Service-Level Agreement (SLA) for Azure Storage even in the face of failures.
However, when deciding which redundancy option is best for your scenario, consider the tradeoffs between lower costs and higher availability and durability. Use factors for determining which redundancy option you should choose, such as:
- Firstly, the process of data replication in the primary region
- Secondly, whether data replication is to a second location that is geographically distant to the primary region, to protect against regional disasters
- Lastly, whether the application requires read access for replicating data in the secondary region if the primary region becomes unavailable for any reason
Primary region redundancy
Data in an Azure Storage account is replicated three times in the primary region. However, Azure Storage provides two options for data replication in the primary region:
- First, Locally redundant storage (LRS) copies your data synchronously three times within a single physical location in the primary region. However, LRS is the least expensive replication option.
- Secondly, Zone-redundant storage (ZRS) copies your data synchronously across three Azure availability zones in the primary region. However, for applications requiring high availability, Microsoft recommends using ZRS in the primary region.
Redundancy in a secondary region
For applications having high availability, you can choose to additionally copy the data in your storage account to a secondary region that is hundreds of miles away from the primary region. And, if your storage account is copied to a secondary region, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
While creating a storage account, you select the primary region for the account. And, the paired secondary region is determined based on the primary region, and can’t be changed. However, Azure Storage provides two options for copying your data to a secondary region:
- Firstly, Geo-redundant storage (GRS), it copies your data synchronously three times within a single physical location in the primary region using LRS. After that, it copies your data asynchronously to a single physical location in the secondary region.
- Secondly, Geo-zone-redundant storage (GZRS), it copies your data synchronously across three Azure availability zones in the primary region using ZRS. After this, it copies your data asynchronously to a single physical location in the secondary region.
The primary difference between GRS and GZRS is how the data replication process is done in the primary region. As in the secondary location, data is always replicated synchronously three times using LRS. Also LRS in the secondary region protects your data against hardware failures. With using GRS or GZRS, the data in the secondary location is not available for reading or writing access unless there is a failover to the secondary region. However, for reading access to the secondary location, first configure your storage account for using reading-access geo-redundant storage (RA-GRS) or reading-access geo-zone-redundant storage (RA-GZRS).
Note:
If the primary region somehow becomes unavailable, then you can choose to fail over to the secondary region. And, after the completion of failover, the secondary region becomes the primary region, and then you can again read and write data.

Read access to data in the secondary region
You should know that Geo-redundant storage (with GRS or GZRS) replicates your data to another physical location in the secondary region for protecting against regional outages. However, the data that is available is for reading only if the customer or Microsoft initiates a failover from the primary to the secondary region. And, after enabling read access to the secondary region, the data can be read at all times. For read access to the secondary region, first enable read-access geo-redundant storage or read-access geo-zone-redundant storage.
Designing applications for read access to the secondary
If storage account configuration is done for reading access to the secondary region, then you can design your applications to shift to reading data from the secondary region if the primary region becomes unavailable for any reason. However, the second region is available for reading access after enabling RA-GRS or RA-GZRS. This is done so that you can test your application in advance to make sure that it will properly read from the secondary in the event of an outage. When read access to the secondary is on, then the application can be read both from the secondary endpoint as well as from the primary endpoint. The secondary endpoint adds the suffix secondary to the account name.
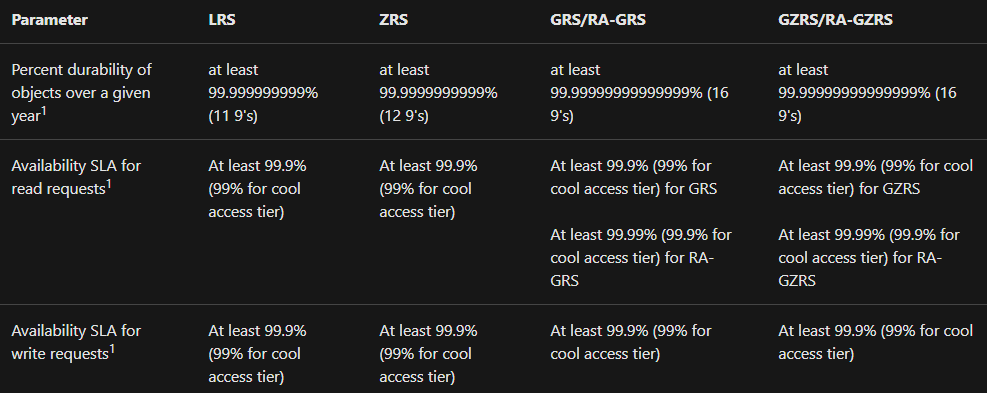
Durability and availability parameters
The table below explains the key parameters for each redundancy option:
Supported storage account types
The table below displays which redundancy options that supports each type of storage account.

Data integrity
Azure Storage regularly checks the ethics of data stored using cyclic redundancy checks (CRCs). However, if there is data corruption, then repairment is using redundant data. Further, Azure Storage also calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data.
Building redundancy into application for avoiding single points failure
For this check the recommendations given below:
Considering business requirements
This explains the amount of redundancy build into a system that can affect both cost and complexity. So, the architecture should get informed by your business requirements, such as recovery time objective (RTO). That is to say, you will require operational procedures for handling failover and failback. As the additional cost and complexity might be justified for some business scenarios and not others.
Placing VMs behind a load balancer
Place multiple VMS behind a load balancer instead of using a single VM for mission-critical workloads. However, if any VM becomes unavailable, then the load balancer distributes traffic to the remaining healthy VMs.
Replicating databases
Azure SQL Database and Cosmos DB are responsible for automatically replicating the data within a region. And, then you can enable geo-replication across regions. However, if you are using an IaaS database solution, then choose the one supporting replication and failover like SQL Server Always On availability groups.
Enabling geo-replication
Geo-replication for Azure SQL Database and Cosmos DB develops secondary readable replicas of your data in one or more secondary regions. And, in the event of an outage, the database can fail over to the secondary region for writes.
Partitioning for availability
Database partitioning is for improving scalability, but it can also improve availability. And, if one shard goes down, the other shards can still be reached. This means, a failure occured in one shard will only damage a subset of the total transactions.
Deployment for more than one region
For getting the highest availability, deploy the application to more than one region. However, in the rare case when a problem affects an entire region, then the application can fail over to another region.
Synchronizing front and backend failover
Azure Traffic Manager is for failing over the front end. And, if the front end becomes unreachable in one region, then Traffic Manager will route new requests to the secondary region. However, you may require to coordinate failing over of the database depending on your database solution.
Using automatic failover but manual failback
For automatic failover use Traffic Manager, but not for automatic failback. As automatic failback carries a risk that you might switch to the primary region before the region is completely healthy. So, first verify that all application subsystems are healthy before manually failing back. Also, you might need to check data consistency before failing back depending on the database.
Including redundancy for Traffic Manager
Traffic Manager is a possible failure point. So, first, review the Traffic Manager SLA, and determine whether using Traffic Manager alone meets your business requirements for high availability. However, if not, then consider adding another traffic management solution as a failback. And, somehow if the Azure Traffic Manager service fails, then change your CNAME records in DNS to point to the other traffic management service.

Reference: Microsoft Documentation, Documentation 2