Query parallelization in Azure Stream Analytics
Microsoft DP-200 exam is getting retired on June 30, 2021. A new replacement exam Data Engineering on Microsoft Azure (DP-203) is available.
In this we will learn how to take advantage of query parallelization in Azure Stream Analytics. And, also about how to scale Stream Analytics jobs by configuring input partitions and tuning the analytics query definition. As a prerequisite, you may want to be familiar with the notion of Streaming Unit described in Understand and adjust Streaming Units.
Partitions in inputs and outputs
Partitioning lets you divide data into subsets based on a partition key. If your input (for example Event Hubs) is partitioned by a key, it is highly recommended to specify this partition key when adding input to your Stream Analytics job. Moreover, scaling a Stream Analytics job takes advantage of partitions in the input and output. And, a Stream Analytics job can consume and write different partitions in parallel, which increases throughput.
Inputs
All Azure Stream Analytics input can take advantage of partitioning:
- Firstly, EventHub (need to set the partition key explicitly with PARTITION BY keyword if using compatibility level 1.1 or below)
- Secondly, IoT Hub (need to set the partition key explicitly with PARTITION BY keyword if using compatibility level 1.1 or below)
- Lastly, Blob storage
Outputs
When you work with Stream Analytics, you can take advantage of partitioning in the outputs:
- Firstly, Azure Data Lake Storage
- Secondly, Azure Functions
- Thirdly, Azure Table
- Then, Blob storage (can set the partition key explicitly)
- Next, Cosmos DB (need to set the partition key explicitly)
- After that, Event Hubs (need to set the partition key explicitly)
- Then, IoT Hub (need to set the partition key explicitly)
- Lastly, Service Bus
Embarrassingly parallel jobs
An embarrassingly parallel job is the most scalable scenario in Azure Stream Analytics. It connects one partition of the input to one instance of the query to one partition of the output. This parallelism has the following requirements:
- Firstly, i f your query logic depends on the same key being processed by the same query instance, you must make sure that the events go to the same partition of your input. For Event Hubs or IoT Hub, this means that the event data must have the PartitionKey value set. Alternatively, you can use partitioned senders. For blob storage, this means that the events are sent to the same partition folder.
- Secondly, for jobs with compatibility level 1.2 or higher (recommended), custom column can be specified as Partition Key in the input settings and the job will be paralellized automatically. Jobs with compatibility level 1.0 or 1.1, requires you to use PARTITION BY PartitionId in all the steps of your query. Multiple steps are allowed, but they all must be partitioned by the same key.
- Next, ost of the outputs supported in Stream Analytics can take advantage of partitioning. If you use an output type that doesn’t support partitioning your job won’t be embarrassingly parallel. For Event Hub outputs, ensure Partition key column is set to the same partition key used in the query. Refer to the output section for more details.
- Lastly, the number of input partitions must equal the number of output partitions. Blob storage output can support partitions and inherits the partitioning scheme of the upstream query. When a partition key for Blob storage is specified, data is partitioned per input partition thus the result is still fully parallel.

Simple query
- Firstly, Input: Event hub with 8 partitions
- Secondly, Output: Event hub with 8 partitions (“Partition key column” must be set to use “PartitionId”)
Query:
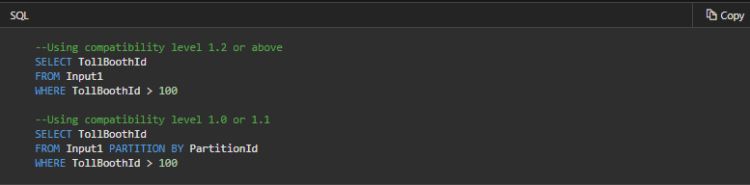
This query is a simple filter. Therefore, we don’t need to worry about partitioning the input that is being sent to the event hub. Notice that jobs with compatibility level before 1.2 must include PARTITION BY PartitionId clause, so it fulfills requirement #2 from earlier. Further, for the output, we need to configure the event hub output in the job to have the partition key set to PartitionId. One last check is to make sure that the number of input partitions is equal to the number of output partitions.
Query with a grouping key
- Firstly, Input: Event hub with 8 partitions
- Secondly, Output: Blob storage
Query:
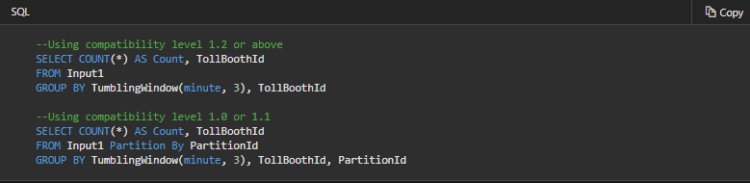
This query has a grouping key. Therefore, the events grouped together must be sent to the same Event Hub partition. Since in this example we group by TollBoothID, we should be sure that TollBoothID is used as the partition key when the events are sent to Event Hub. Then in ASA, we can use PARTITION BY PartitionId to inherit from this partition scheme and enable full parallelization. Since the output is blob storage, we don’t need to worry about configuring a partition key value, as per requirement #4.
Multi-step query with different PARTITION BY values
- Firstly, Input: Event hub with 8 partitions
- Secondly, Output: Event hub with 8 partitions
- Thirdly, Compatibility level: 1.0 or 1.1
Query:
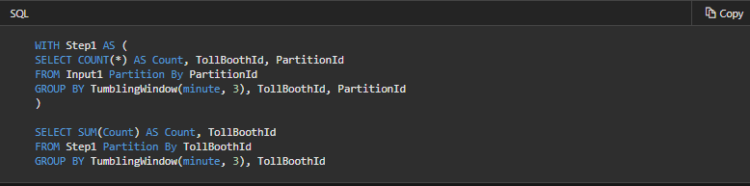
As you can see, the second step uses TollBoothId as the partitioning key. This step is not the same as the first step, and it therefore requires us to do a shuffle.
Calculate the maximum streaming units of a job
The total number of streaming units that can be used by a Stream Analytics job depends on the number of steps in the query defined for the job and the number of partitions for each step.
Steps in a query
A query can have one or many steps. Each step is a subquery defined by the WITH keyword. However, the query that is outside the WITH keyword (one query only) is also counted as a step, such as the SELECT statement in the following query:
Query:
SQL
WITH Step1 AS (
SELECT COUNT(*) AS Count, TollBoothId
FROM Input1 Partition By PartitionId
GROUP BY TumblingWindow(minute, 3), TollBoothId, PartitionId
)
SELECT SUM(Count) AS Count, TollBoothId
FROM Step1
GROUP BY TumblingWindow(minute,3), TollBoothId
This query has two steps.

Reference: Microsoft Documentation