Optimize Azure Data Lake Storage Gen2 for performance
To optimize Azure Data Lake Storage Gen2 for performance, you can take the following steps:
- Choose the right file format: Choose a file format that is optimized for your specific use case. For example, if you are working with text data, consider using formats like Parquet or ORC, which are designed for efficient columnar storage and retrieval. If you are working with binary data, consider using formats like Avro or ProtoBuf, which offer compact serialization and deserialization.
- Optimize block size: Block size can affect performance significantly. For workloads that involve large files, a larger block size can improve performance. However, for small files, a smaller block size can reduce latency. You can experiment with different block sizes to find the optimal setting for your workload.
- Use Azure Blob Storage Lifecycle Management: Lifecycle Management can help you manage the lifecycle of your data by automatically moving data to a lower-cost storage tier or deleting it when it is no longer needed. This can help you optimize your storage costs while maintaining performance.
- Use caching: Caching can help reduce latency and improve performance by storing frequently accessed data in memory. You can use Azure Data Lake Storage Gen2’s built-in caching or implement your own caching solution.
- Use partitioning: Partitioning can help improve query performance by limiting the amount of data scanned. You can partition your data based on different criteria, such as date, location, or user. This can help you optimize performance for specific queries or workloads.
- Use Azure Data Lake Storage Gen2 analytics: Azure Data Lake Storage Gen2 analytics can provide insights into your data usage patterns, allowing you to optimize your storage and performance. You can use analytics to identify hotspots in your data and optimize your partitioning and caching strategies accordingly.
By following these steps, you can optimize your Azure Data Lake Storage Gen2 for performance and achieve faster query times, lower latency, and reduced costs.
Additional reference links for Microsoft Documenation:
1. Azure Data Lake Store Gen2 performance considerations (IOPS) and single/multiple accounts
2. Best practices for using Azure Data Lake Storage Gen2
Sample Questions
- What is a recommended approach to optimize performance when storing data in Azure Data Lake Storage Gen2?
a) Store all data in a single file
b) Store data in many small files
c) Utilize folder structures and larger file sizes
d) None of the above - What can be done to optimize query performance when working with time-series data in Hive?
a) Partition pruning
b) Storing data in multiple small files
c) Replicating data across different partitions
d) None of the above - What is the role of YARN in optimizing Azure Data Lake Storage Gen2 performance?
a) Resource negotiator
b) Data ingestion tool
c) Query optimizer
d) None of the above - What is the benefit of using smaller YARN containers?
a) Fewer containers can be created
b) Larger containers can handle more tasks
c) More containers can be created to maximize resource utilization
d) None of the above - What is a best practice for running jobs in Azure Data Lake Storage Gen2 to improve performance?
a) Run containers sequentially to ensure consistency
b) Use a smaller number of parallel containers to avoid resource contention
c) Run as many parallel containers as possible to maximize resource utilization
d) None of the above
Answer:
- c) Utilize folder structures and larger file sizes
- a) Partition pruning
- a) Resource negotiator
- c) More containers can be created to maximize resource utilization
- c) Run as many parallel containers as possible to maximize resource utilization
Let’s learn in detail
Azure Data Lake Storage Gen2 supports high-throughput for I/O intensive analytics and data movement. To achieve optimal performance in Data Lake Storage Gen2, it is crucial to utilize the full available throughput, which refers to the amount of data that can be written or read within a second. This can be accomplished by performing numerous parallel reads and writes.
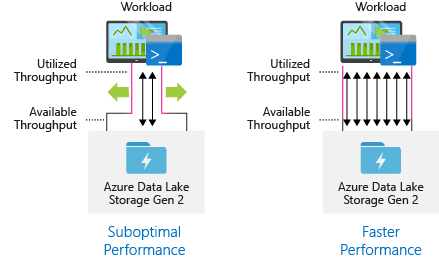
However, data Lake Storage Gen2 can scale to provide the necessary throughput for all analytics scenario. By default, a Data Lake Storage Gen2 account provides automatically enough throughput to meet the needs of a broad category of use cases. For the cases where customers run into the default limit, the Data Lake Storage Gen2 account can be configured to provide more throughput by contacting Azure Support.
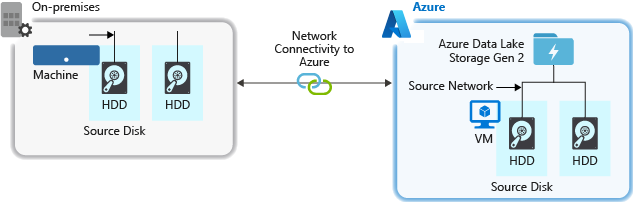
Data ingestion
When ingesting data from a source system to Data Lake Storage Gen2, it is important to consider that the source hardware, source network hardware, and network connectivity to Data Lake Storage Gen2 can be the bottleneck.
Structure your data set
The way data is stored in Data Lake Storage Gen2 can greatly influence its performance, particularly in terms of file size, number of files, and folder structure.
File size
It is important to adhere to best practices in these areas. Analytics engines like HDInsight and Azure Data Lake Analytics typically incur a per-file overhead. Storing data in multiple small files can result in decreased performance. In general, organize your data into larger sized files for better performance (256MB to 100GB in size). However, some engines and applications might have trouble efficiently processing files that are greater than 100GB in size.

Organizing time series data in folders
In Hive workloads, partition pruning can be useful for time-series data as it enables certain queries to read only the required subset of data, leading to improved performance. However, pipelines that process time-series data typically organize their files and folders with highly structured naming conventions. The following example is a common practice for structuring data by date.
For date and time, the following is a common pattern
\DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv
Optimizing I/O intensive jobs on Hadoop and Spark workloads on HDInsight
Jobs fall into one of the following three categories:
- Firstly, CPU intensive. These jobs have long computation times with minimal I/O times. Examples include machine learning and natural language processing jobs.
- Secondly, Memory intensive. These jobs use lots of memory. Examples include PageRank and real-time analytics jobs.
- Lastly, I/O intensive. These jobs spend most of their time doing I/O. A common example is a copy job which does only read and write operations.
General considerations for an HDInsight cluster
- Firstly, HDInsight versions. For best performance, use the latest release of HDInsight.
- Secondly, Regions. Place the Data Lake Storage Gen2 account in the same region as the HDInsight cluster.
However, an HDInsight cluster is composed of two head nodes and some worker nodes. The VM-type determines the number of cores and amount of memory provided by each worker node. During job execution, YARN acts as the resource negotiator and allocates available memory and cores to create containers. These containers perform the necessary tasks to accomplish the job, and running them in parallel can speed up processing. Therefore, maximizing the number of parallel containers can enhance performance.
There are three layers within an HDInsight cluster that can be tuned to increase the number of containers and use all available throughput.
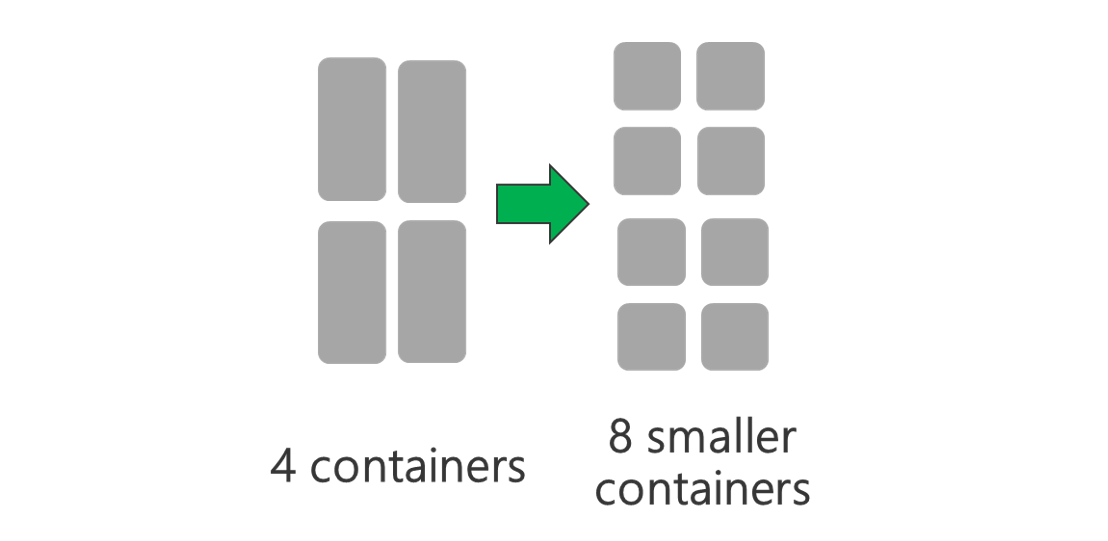
- Physical Layer
Run cluster with more nodes and/or larger sized VMs. A larger cluster will enable you to run more YARN containers as shown in the picture below.

Use VMs with more network bandwidth. The amount of network bandwidth can be a bottleneck if there is less network bandwidth than Data Lake Storage Gen2 throughput. Different VMs will have varying network bandwidth sizes. Choose a VM-type that has the largest possible network bandwidth.
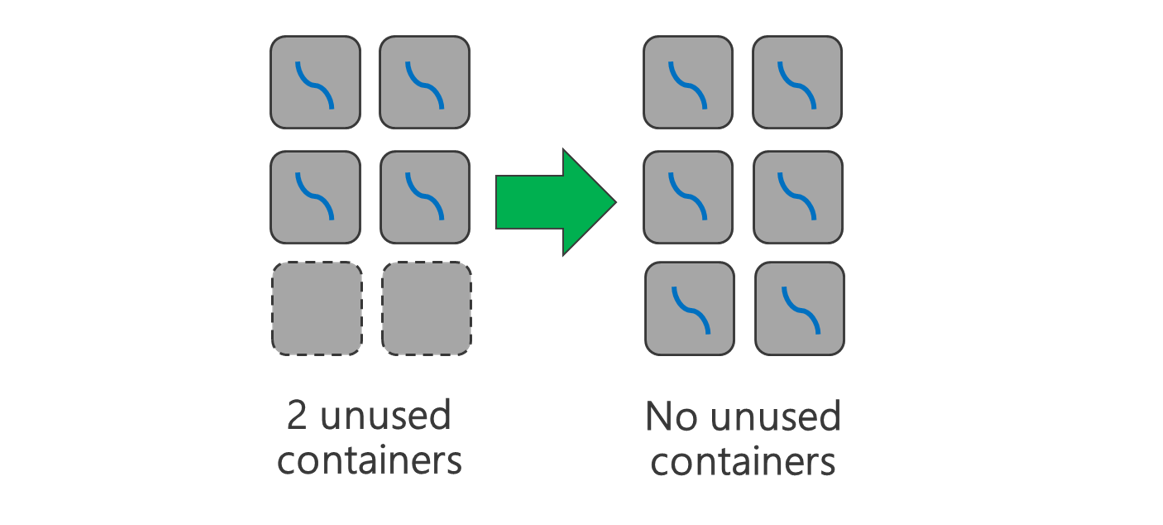
2. YARN Layer
To increase the number of containers and maximize resource utilization, it is advisable to use smaller YARN containers. By reducing the size of each YARN container, more containers can be created while still utilizing the same amount of resources.
Depending on your workload, there will always be a minimum YARN container size that is needed. If you pick too small a container, your jobs will run into out-of-memory issues. Typically YARN containers should be no smaller than 1GB. It’s common to see 3GB YARN containers. For some workloads, you may need larger YARN containers.
3. Workload Layer
To fully utilize available resources, it is recommended to use all containers. This can be achieved by setting the number of tasks equal to or greater than the number of available containers, ensuring that all resources are utilized.
.

Reference: Microsoft Documentation