Implement data distribution and partitions for Azure Synapse Analytics
Microsoft DP-200 exam is retired. A new replacement exam Data Engineering on Microsoft Azure (DP-203) is available.
In this we will learn about configuring a database in SQL Database and client application for failover with partitioning tables. And, we will get familiar with familiar with data distribution and data movement concepts in dedicated SQL pool.
Run the sample project
- Firstly, in the console, create a Maven project with the following command:
Bash
mvn archetype:generate “-DgroupId=com.sqldbsamples” “-DartifactId=SqlDbSample” “-DarchetypeArtifactId=maven-archetype-quickstart” “-Dversion=1.0.0”
- Secondly, type Y and press Enter.
- Then, change directories to the new project.
Bash
cd SqlDbSample
- Using your favorite editor, open the pom.xml file in your project folder.
- Then, add the Microsoft JDBC Driver for SQL Server dependency by adding the following dependency section. The dependency must be pasted within the larger dependencies section.
- After that, specify the Java version by adding the properties section after the dependencies section.
- Next, support manifest files by adding the build section after the properties section:
- Then, save and close the pom.xml file.
- Open the App.java file located in ..\SqlDbSample\src\main\java\com\sqldbsamples and replace the contents with the code.
- Then, save and close the App.java file.
- After that, in the command console, run the following command:
Bash
mvn package
- Lastly, start the application that will run for about 1 hour until stopped manually, allowing you time to run the failover test.
Partitioning tables in dedicated SQL pool
Table partitions enable you to divide your data into smaller groups of data. In most cases, table partitions are created on a date column. Partitioning is supported on all dedicated SQL pool table types; including clustered columnstore, clustered index, and heap. Partitioning is also supported on all distribution types, including both hash or round robin distributed.
Benefits to loads
The primary benefit of partitioning in dedicated SQL pool is to improve the efficiency and performance of loading data by use of partition deletion, switching and merging. In most cases data is partitioned on a date column that is closely tied to the order in which the data is loaded into the SQL pool. One of the greatest benefits of using partitions to maintain data is the avoidance of transaction logging. While simply inserting, updating, or deleting data can be the most straightforward approach, with a little thought and effort, using partitioning during your load process can substantially improve performance.
Benefits to queries
Partitioning can also be used to improve query performance. A query that applies a filter to partitioned data can limit the scan to only the qualifying partitions. This method of filtering can avoid a full table scan and only scan a smaller subset of data. With the introduction of clustered columnstore indexes, the predicate elimination performance benefits are less beneficial, but in some cases there can be a benefit to queries.
Sizing partitions
- Firstly, while partitioning can be used to improve performance some scenarios, creating a table with too many partitions can hurt performance under some circumstances. These concerns are especially true for clustered columnstore tables.
- Secondly, for partitioning to be helpful, it is important to understand when to use partitioning and the number of partitions to create. There is no hard fast rule as to how many partitions are too many, it depends on your data and how many partitions you loading simultaneously.
- Lastly, when creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed.
Syntax differences from SQL Server
Dedicated SQL pool introduces a way to define partitions that is simpler than SQL Server. Partitioning functions and schemes are not used in dedicated SQL pool as they are in SQL Server. Instead, all you need to do is identify partitioned column and the boundary points.
While the syntax of partitioning may be slightly different from SQL Server, the basic concepts are the same. SQL Server and dedicated SQL pool support one partition column per table, which can be ranged partition.
The following example uses the CREATE TABLE statement to partition the FactInternetSales table on the OrderDateKey column:
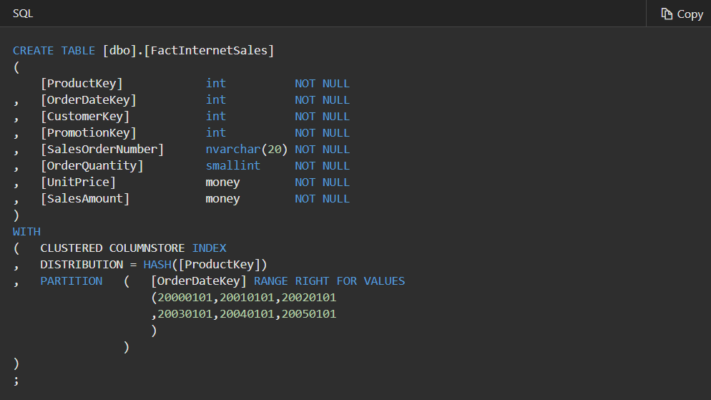
Load new data into partitions that contain data in one step
- Firstly, loading data into partitions with partition switching is a convenient way to stage new data in a table that is not visible to users. It can be challenging on busy systems to deal with the locking contention associated with partition switching.
- Secondly, to clear out the existing data in a partition, an ALTER TABLE used to be required to switch out the data. Then another ALTER TABLE was required to switch in the new data.
- Lastly, in dedicated SQL pool, the TRUNCATE_TARGET option is supported in the ALTER TABLE command. With TRUNCATE_TARGET the ALTER TABLE command overwrites existing data in the partition with new data.
Guidance for designing distributed tables using dedicated SQL pool in Azure Synapse Analytics
What is a distributed table?
A distributed table appears as a single table, but the rows are actually stored across 60 distributions. The rows are distributed with a hash or round-robin algorithm.
Hash-distributed tables improve query performance on large fact tables, and are the focus of this article. Round-robin tables are useful for improving loading speed. These design choices have a significant impact on improving query and loading performance.
However, a hash-distributed table distributes table rows across the Compute nodes by using a deterministic hash function to assign each row to one distribution.

Since identical values always hash to the same distribution, SQL Analytics has built-in knowledge of the row locations. In dedicated SQL pool this knowledge is used to minimize data movement during queries, which improves query performance.
Hash-distributed tables work well for large fact tables in a star schema. They can have very large numbers of rows and still achieve high performance. There are, of course, some design considerations that help you to get the performance the distributed system is designed to provide.

Round-robin distributed
- A round-robin distributed table distributes table rows evenly across all distributions. The assignment of rows to distributions is random. Unlike hash-distributed tables, rows with equal values are not guaranteed to be assigned to the same distribution.
- As a result, the system sometimes needs to invoke a data movement operation to better organize your data before it can resolve a query. This extra step can slow down your queries.
- However, consider using the round-robin distribution for your table in the following scenarios:
- Firstly, when getting started as a simple starting point since it is the default
- Secondly, if there is no obvious joining key
- Thirdly, if there is no good candidate column for hash distributing the table
- Next, if the table does not share a common join key with other tables
- Lastly, if the join is less significant than other joins in the query.
Choosing a distribution column
A hash-distributed table has a distribution column that is the hash key. For example, the following code creates a hash-distributed table with ProductKey as the distribution column.
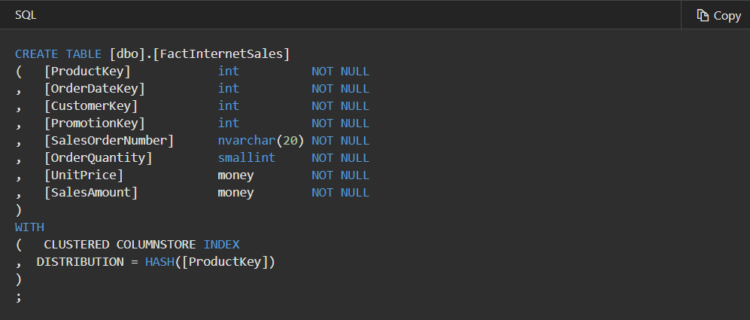
Choosing a distribution column is an important design decision since the values in this column determine how the rows are distributed. The best choice depends on several factors, and usually involves tradeoffs. Once a distribution column is chosen, you cannot change it.
Choose a distribution column that minimizes data movement
To get the correct query result queries might move data from one Compute node to another. Data movement commonly happens when queries have joins and aggregations on distributed tables. Choosing a distribution column that helps minimize data movement is one of the most important strategies for optimizing performance of your dedicated SQL pool.
To minimize data movement, select a distribution column that:
- Firstly, is used in JOIN, GROUP BY, DISTINCT, OVER, and HAVING clauses. When two large fact tables have frequent joins, query performance improves when you distribute both tables on one of the join columns. When a table is not used in joins, consider distributing the table on a column that is frequently in the GROUP BY clause.
- Secondly, is not used in WHERE clauses. This could narrow the query to not run on all the distributions.
- Lastly, is not a date column. WHERE clauses often filter by date. When this happens, all the processing could run on only a few distributions.
Check query plans for data movement
A good distribution column enables joins and aggregations to have minimal data movement. This affects the way joins should be written. To get minimal data movement for a join on two hash-distributed tables, one of the join columns needs to be the distribution column. When two hash-distributed tables join on a distribution column of the same data type, the join does not require data movement. Joins can use additional columns without incurring data movement.
To avoid data movement during a join:
- Firstly, the tables involved in the join must be hash distributed on one of the columns participating in the join.
- Secondly, the data types of the join columns must match between both tables.
- Thirdly, the columns must be joined with an equals operator.
- Lastly, the join type may not be a CROSS JOIN.

Reference: Microsoft Documentation, Documentation 2, Documentation 3