Data process in Azure Synapse Analytics using Azure Data Factory
Azure Synapse Analytics is a cloud-based analytics service that enables organizations to analyze large volumes of data and extract insights. Azure Data Factory is a cloud-based data integration service that allows you to create data pipelines that move data from various sources to Azure Synapse Analytics for processing. Here are the steps involved in data processing in Azure Synapse Analytics using Azure Data Factory:
- Create an Azure Synapse Analytics workspace: To use Azure Synapse Analytics, you need to create a workspace in the Azure portal. A workspace is a container for your data, pipelines, and other artifacts.
- Create an Azure Data Factory instance: After creating an Azure Synapse Analytics workspace, the next step is to create an Azure Data Factory instance. This instance will act as a platform for building data pipelines that will move data from various sources to Azure Synapse Analytics.
- Create a data pipeline: With Azure Data Factory, you can create data pipelines that move data from various sources to Azure Synapse Analytics for processing. You can use the Azure portal or Azure Data Factory UI to create the pipeline.
- Define the source and destination: In the data pipeline, you need to define the source of the data and the destination where the data will be processed. You can choose from various data sources such as Azure Blob Storage, Azure SQL Database, or on-premises SQL Server.
- Transform the data: In Azure Data Factory, you can use Data Flow to transform and process data. Data Flow is a cloud-based data transformation service that allows you to create data flows visually. You can use transformations such as sorting, filtering, and aggregating data.
- Run the pipeline: After defining the data pipeline, you can run it to move data from the source to Azure Synapse Analytics. You can monitor the pipeline run and view the data processing metrics in the Azure portal.
- Analyze the data: With the data in Azure Synapse Analytics, you can use tools such as Azure Synapse Studio to analyze the data and extract insights. You can create SQL scripts or use drag-and-drop visualizations to analyze the data.
Azure Synapse Analytics and Azure Data Factory provide a powerful combination for processing and analyzing data in the cloud. With Azure Data Factory, you can create data pipelines that move data from various sources to Azure Synapse Analytics, where you can analyze the data and extract insights.
Prerequisites to Load data into Azure Synapse Analytics using Azure Data Factory or a Synapse pipeline
Before you can load data into Azure Synapse Analytics using Azure Data Factory, you need to meet the following prerequisites:
- Create an Azure Synapse Analytics workspace: You need to create a workspace in Azure Synapse Analytics. You can create a workspace using the Azure portal, Azure PowerShell, Azure CLI, or the Azure Synapse Studio.
- Create an Azure Data Factory: You need to create an Azure Data Factory in your Azure subscription. You can create a data factory using the Azure portal, Azure PowerShell, Azure CLI, or Azure Data Factory REST API.
- Add a linked service: You need to add a linked service to connect to the data source you want to copy data from. Linked services define the connection properties for the data store, including authentication and security information.
- Create a dataset: You need to create a dataset that defines the schema and format of the data source. The dataset specifies the location and format of the data to be copied, as well as any transformations or mapping required.
- Create a pipeline: You need to create a pipeline to define the workflow for the data copy operation. A pipeline consists of a set of activities that define the actions to be performed on the data, such as copying data, transforming data, or executing stored procedures.
- Run the pipeline: Once you have created a pipeline, you can run it to copy data from the source data store to Azure Synapse Analytics. You can monitor the progress of the pipeline using Azure Synapse Studio or the Azure portal.
Microsoft Documentation Reference Link – Load data into Azure Synapse Analytics using Azure Data Factory
Copy and transform data in Azure Synapse Analytics by using Azure Data Factory or Synapse pipelines
Azure Synapse Analytics Practice Exam Questions
1. Your organization needs to process a large amount of data on a regular basis. Which Azure Synapse Analytics feature should you use to handle the workload?
A. Azure Blob Storage
B. Azure Data Lake Storage
C. PolyBase
D. Azure Data Factory
2. Your organization has data stored in on-premises SQL Server databases, and you want to move it to Azure Synapse Analytics. Which Azure service should you use?
A. Azure Blob Storage
B. Azure Data Lake Storage
C. Azure Data Factory
D. Azure Synapse Studio
3. Your organization wants to analyze data from various sources, including relational and non-relational data. Which feature of Azure Synapse Analytics should you use?
A. PolyBase
B. Azure Synapse Studio
C. Azure Data Factory
D. Azure Blob Storage
4. Your organization needs to extract insights from data stored in Azure Synapse Analytics. Which tool should you use?
A. Azure Data Factory
B. PolyBase
C. Azure Synapse Studio
D. Azure Blob Storage
5. Your organization wants to load data into Azure Synapse Analytics from various sources, including on-premises SQL Server databases and Azure Blob Storage. Which feature of Azure Synapse Analytics should you use?
A. Azure Synapse Studio
B. PolyBase
C. Azure Data Factory
D. Azure Blob Storage
Answers:
1. (C) PolyBase
Explanation – PolyBase is the most efficient way to handle large data volumes in Azure Synapse Analytics.
2. (C) Azure Data Factory
Azure Data Factory is a fully managed cloud-based data integration service that enables you to move data from various sources, including on-premises SQL Server databases, to Azure Synapse Analytics.
3. (B) Azure Synapse Studio
Azure Synapse Studio is an all-in-one analytics studio that enables you to perform data exploration and analysis on relational and non-relational data sources.
4. (C) Azure Synapse Studio
Azure Synapse Studio provides a range of tools, including SQL scripts, drag-and-drop visualizations, and machine learning models, to extract insights from data stored in Azure Synapse Analytics.
5. (C) Azure Data Factory
Azure Data Factory is a fully managed cloud-based data integration service that enables you to move data from various sources, including on-premises SQL Server databases and Azure Blob Storage, to Azure Synapse Analytics.
More Practice Exam Questions on AZ-305…
About Azure Synapse Analytics
Lets learn about the Azure Synapse Analytics in detail –
Supported capabilities
For Copying activity, the Azure Synapse Analytics connector supports these functions:
- Firstly copying data by using SQL authentication and Azure Active Directory Application token authentication with a service principal or managed identities for Azure resources.
- Secondly, as a source, retrieving data by using a SQL query or stored procedure.
- Lastly, like a sink, loading data by using PolyBase or COPY statements or bulk insert. It is recommended to use PolyBase or COPY statement (preview) for better copy performance.
However, for performing the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- Firstly, the Copy Data tool
- Secondly, the Azure portal
- Thirdly, .NET SDK
- Then, Python SDK
- Azure PowerShell
- REST API
- Lastly, the Azure Resource Manager template
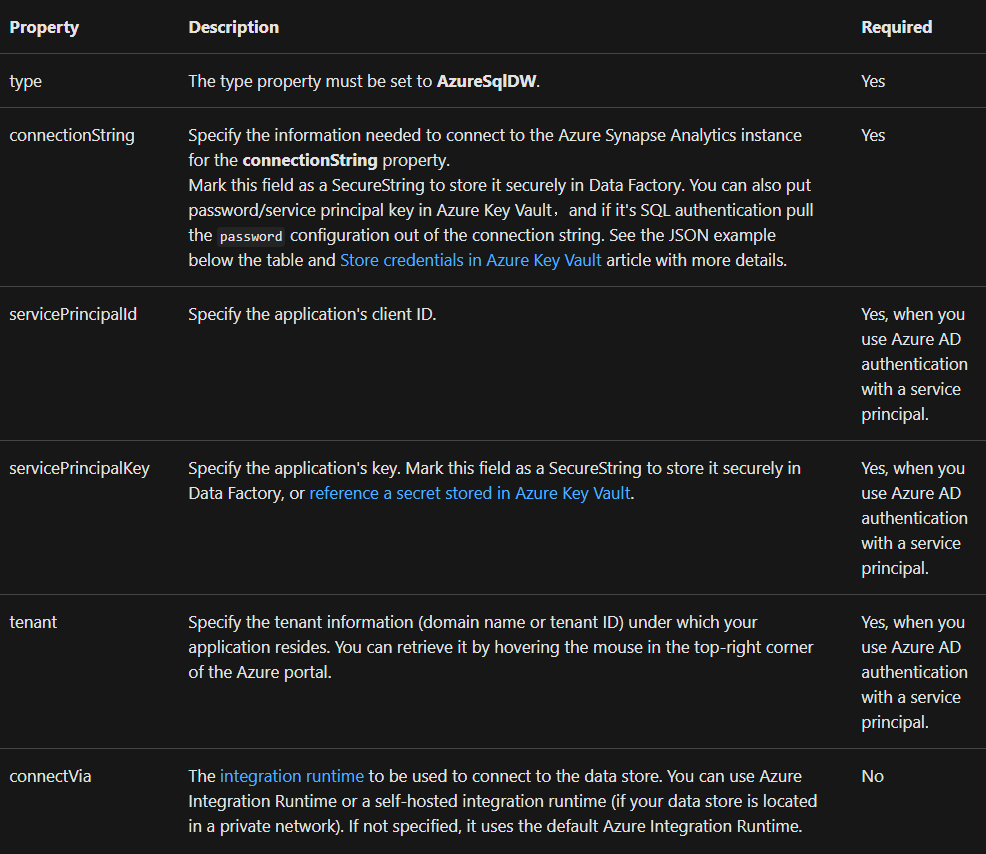
Linked service properties
The properties below are supported for an Azure Synapse Analytics linked service:
Service principal authentication
For using service principal-based Azure AD application token authentication, follow these steps:
- Firstly, create an Azure Active Directory application from the Azure portal. And, make note of the application name with the following values that define the linked service such as Application ID, Application key and Tenant ID.
- Secondly, provision an Azure Active Directory administrator for your server in the Azure portal. However, the Azure AD administrator can be an Azure AD user or Azure AD group. And, if you grant the group with managing identity for an admin role, then skip steps 3 and 4. Moreover, the administrator will have full access to the database.
- Thirdly, create contained database users for the service principal. Moreover, connect to the data warehouse from or to which you want to copy data by using tools. The tools here include SSMS that has an Azure AD identity with at least ALTER ANY USER permission. Run the following T-SQL:
SQL
CREATE USER [your application name] FROM EXTERNAL PROVIDER;
- After that, grant the service principal that requires permissions. Then, Run the following code:
SQL
EXEC sp_addrolemember db_owner, [your application name];
- Lastly, configure an Azure Synapse Analytics linked service in Azure Data Factory.

Managed identities for Azure resources authentication
A managed identity for Azure resources representing the specific factory may be linked to a data factory. This managed identity, on the other hand, maybe used for Azure Synapse Analytics authentication. Using this identity, the selected factory can access and copy data from or to your data warehouse.
For using managed identity authentication, follow these steps:
- Firstly, provision an Azure Active Directory administrator for your server on the Azure portal. You should know that the Azure AD administrator can be an Azure AD user or Azure AD group. However, if you grant the group with managed identity an admin role, then skip steps 3 and 4.
- After that, create contained database users for the Data Factory Managed Identity. Thne, connect to the data warehouse from or to which you want to copy data by using tools. The tools include SSMS, with an Azure AD identity that has at least ALTER ANY USER permission. Then, run the following T-SQL.
SQL
CREATE USER [your Data Factory name] FROM EXTERNAL PROVIDER;
- Then, grant the Data Factory Managed Identity that requires permissions. After this, run the following code:
SQL
EXEC sp_addrolemember db_owner, [your Data Factory name];
- Lastly, configure an Azure Synapse Analytics linked service in Azure Data Factory.
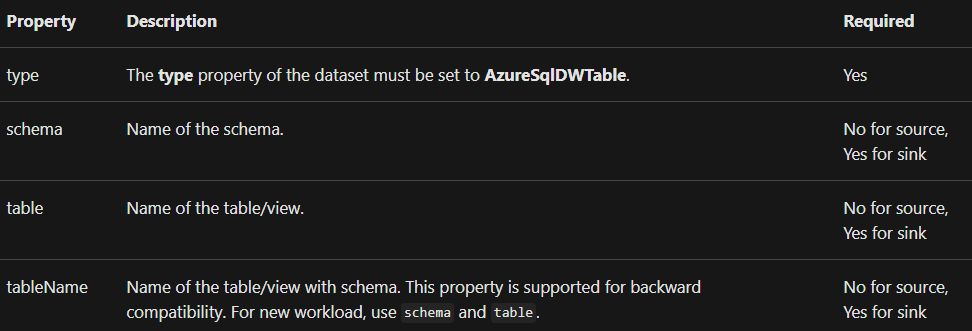
Dataset properties
Check the properties that support Azure Synapse Analytics dataset below:
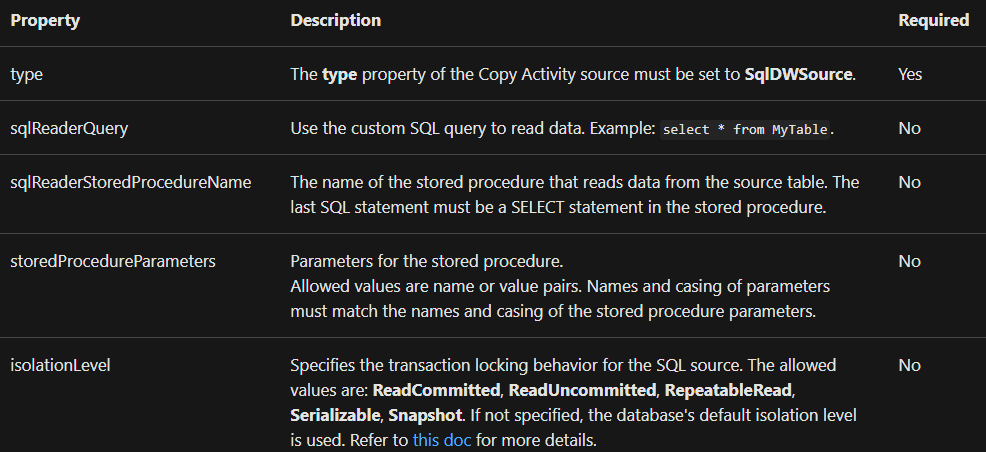
Azure Synapse Analytics as the source
Set the type property in the Copy Activity source to SqlDWSource to copy data from Azure Synapse Analytics. The Copy Activity source section is supported by the characteristics listed below:
Using PolyBase for loading data into Azure SQL Data Warehouse
Using PolyBase is a fast and effective approach to importing a huge quantity of data into Azure Synapse Analytics. Further, using PolyBase instead of the normal BULKINSERT method results in a significant increase in throughput. Check out Load 1 TB into Azure Synapse Analytics for a walkthrough with a use case.
- Firstly, if your source data is in Azure Blob, Azure Data Lake Storage Gen1, or Azure Data Lake Storage Gen2, and the format is PolyBase compatible. Then, you can use copy activity for directly invoking PolyBase to let Azure SQL Data Warehouse pull the data from the source.
- Secondly, if your source data store and format aren’t originally supported by PolyBase. Then, use the Staged copy by using the PolyBase feature instead. However, the staged copy feature also provides you better throughput as it automatically converts the data into PolyBase-compatible format. Then it stores the data in Azure Blob storage and calls PolyBase for loading data into SQL Data Warehouse.
Mapping data flow properties
Simply read and write to tables from Azure Synapse Analytics while altering data in the mapping data flow. Check out the source and sink transformations in mapping data flows to have a better understanding of this.
Source transformation
In the Source Options tab of the source transformation, the settings specific to Azure Synapse Analytics is available.
- Firstly, Input. In this, select whether you point your source at a table (the equivalent of Select * from <table-name>) or enter a custom SQL query.
- Secondly, Enable Staging. Use this option in production workloads with Synapse DW sources. That is to say when you execute a data flow activity with Synapse sources from a pipeline. Then, ADF will prompt you for a staging location storage account and will use that for staged data loading. Moreover, it is the fastest mechanism for loading data from Synapse DW.
- After that, Query. Select Query in the input field, then enters a SQL query for your source. This setting will override any table that you’ve chosen in the dataset. Order By clauses is not supported here, but you can set a full SELECT FROM statement. However, you can also use user-defined table functions, “select * from udfGetData()” is a UDF in SQL that returns a table. This query is for producing a source table that you can use in your data flow.
- Then, Batch size. Enter a batch size for chunking large data into reads. However, in data flows, ADF will use this setting to set Spark columnar caching.
- Lastly, the Isolation Level. You can change the isolation level with the values such as Read Committed, Read Uncommitted, Repeatable Read and Serializable *- None.
Sink transformation
The options related to Azure Synapse Analytics are available in the Source Options tab of the sink transformation.
- Firstly, there is the Update method. This determines what operations are allowed on your database destination. However, the default is to only allow inserts. And, for updating, upserting, or deleting rows, an alter-row transformation is necessary to tag rows for those actions. For this, a key column or columns must set for determining which row to alter.
- Then, Table action. This determines whether to recreate or remove all rows from the destination table prior to writing.
The table action covers:
None, which No action will be done to the table.
Recreate, using this the table will get dropped and recreated.
Then, Truncate, in this All rows from the target table will get removed.
- Thirdly, Enable staging that determines whether or not to use PolyBase when writing to Azure Synapse Analytics
- Fourthly, Batch size. This controls how many rows are being written in each bucket. However, larger batch sizes improve compression and memory optimization but risk out of memory exceptions when caching data.
- Lastly, Pre, and Post SQL scripts. This is for entering multi-line SQL scripts that will execute before and after data is written to your Sink database

Reference: Microsoft Documentation