
Managing data and using it for services is a big task for organizations. There is a requirement for the platform to take care of all the processes for data functioning. Related to this, Microsoft provides relief to organizations and businesses by introducing Azure Databricks.
By using Big data analytics and AI with optimized Apache Spark, Azure Databricks provides a fast, simple, and collaborative Apache SparkTM based analytics service. This provides insights for all your data and,
- Firstly, builds artificial intelligence (AI) solutions
- Secondly, set up your Apache Spark environment
- Thirdly, autoscaling, and collaborating on shared projects in an interactive workspace.
Want to learn more about Azure Databricks? Then, be a part of this journey. In this blog, we will understand Azure Databricks in a step-wise manner starting from an overview and then, covering its other important details. So, let’s begin!
What is Azure Databricks?
Azure Databricks refers to a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks supports languages like Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries that include TensorFlow, PyTorch, and sci-kit-learn. Further, this comes with two environments for developing data-intensive applications
Azure Databricks SQL Analytics
- Azure Databricks SQL Analytics provides a simple platform for analysts to run SQL queries on their data lake. This helps in creating multiple visualization types for exploring query results from different perspectives, and build and share dashboards.
Azure Databricks Workspace
- On the other hand, Azure Databricks Workspace provides an interactive workspace for enabling collaboration between data engineers, data scientists, and machine learning engineers. However, for a big data pipeline, the data is ingested into Azure through Azure Data Factory in batches.

Features:
- Firstly, Azure Databricks provides the latest versions of Apache Spark with seamless integration with open source libraries. Using this, spin up clusters and build quickly in a fully managed Apache Spark environment using the global scale and availability of Azure. Clusters are set up, configured, and fine-tuned for ensuring reliability and performance without the need for monitoring.
- Secondly, it boosts productivity with a shared workspace and common languages. This lets you collaborate effectively on an open and unified platform for running all types of analytics workloads. Moreover, build with your own choice of languages like Python, Scala, R, and SQL.
- Thirdly, this provides access to advanced automated machine learning capabilities using the integrated Azure Machine Learning for identifying suitable algorithms and hyperparameters. Moreover, Azure Machine Learning also provides a central registry for your experiments, machine learning pipelines, and models.
- Lastly, this provides high-performance modern data warehousing. That is to say, you can combine data at any scale and get insights through analytical dashboards and operational reports. Moreover, you can automate data movement using Azure Data Factory. And, then load data into Azure Data Lake Storage by transforming and cleaning it using Azure Databricks and making it available for analytics using Azure Synapse Analytics.
Azure Databricks: Key service capabilities
1. Optimized spark engine
- Azure Databricks provides easy-to-use data processing on autoscaling infrastructure with highly optimized Apache Spark performance.
2. Machine learning run time
- It offers one-click access for pre-configured machine learning environments for augmented machine learning. This comes with popular frameworks like PyTorch, TensorFlow, and sci-kit-learn.
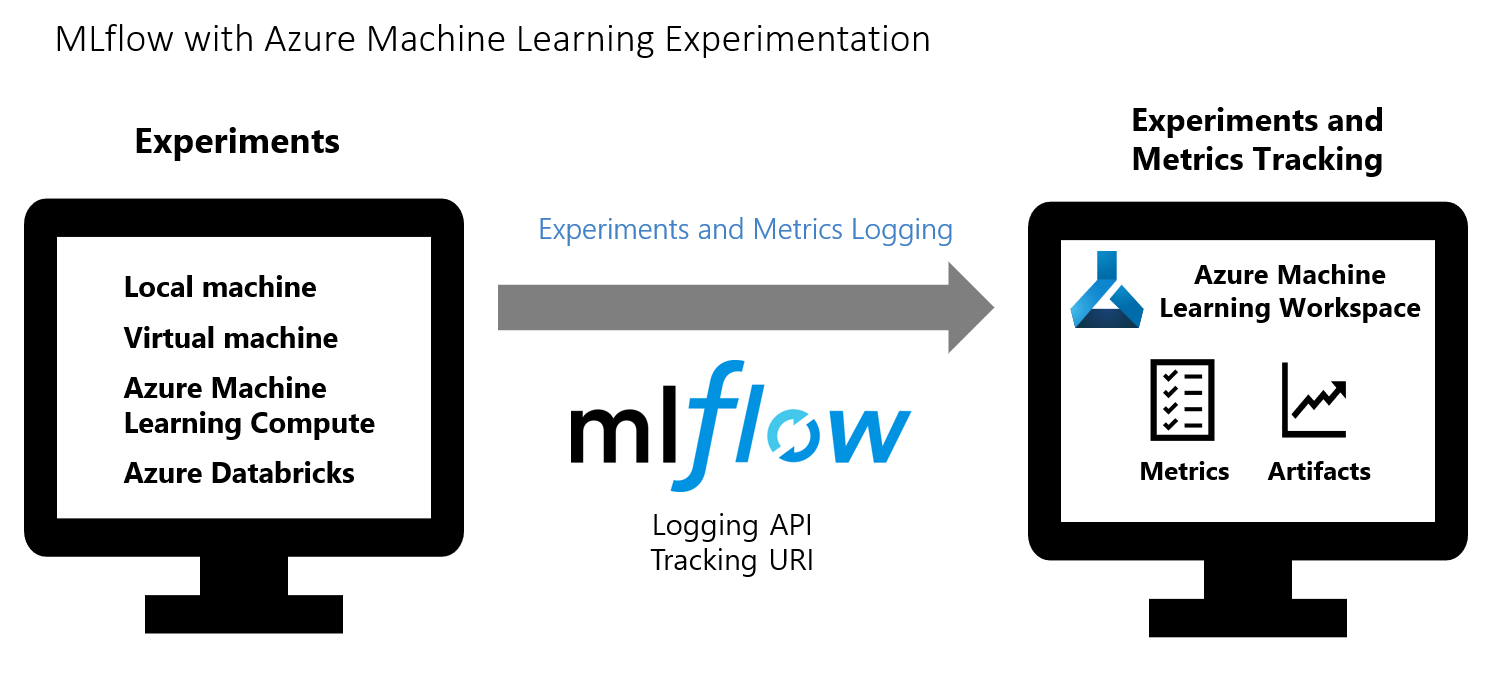
3. MLflow
This is for:
- Firstly, tracking and sharing experiments
- Secondly, reproduce running and managing models collaboratively from a central repository.
4. Choice of language
- You can use your preferred language that can be Python, Scala, R, Spark SQL, and .Net. This works whether you use serverless or provisioned compute resources.
5. Collaborative notebooks
In this,
- Firstly, quickly access and explore data
- Secondly, find and share new insights
- Lastly, build models collaboratively with the languages and tools of your choice.
6. Delta lake
- This provides an open-source transactional storage layer designed for the full data lifecycle by bringing data reliability and scalability to your existing data lake.
7. Native integrations with Azure services
- Use Azure services like Azure Data Factory, Azure Data Lake Storage, Azure Machine Learning, and Power BI for completing end-to-end analytics and machine learning solution with deep integration.
8. Interactive workspaces
- This lets you enable seamless collaboration between data scientists, data engineers, and business analysts.
9. Enterprise-grade security
- This offers native security for data protection and creates compliant, private, and isolated analytics workspaces across thousands of users and datasets.
10. Production-ready
- Using ecosystem integrations for CI/CD and monitoring for running and scaling most mission-critical data workloads on a trusted data platform.
We have understood the basic features and capabilities of Azure Databricks. Let’s take a look at some of Databrick’s major examples.
Solution architecture examples in Azure Databricks
1. Real-Time Analytics on Big Data Architecture
This provides insights from live streaming data with ease. This allows you to capture data from any IoT device. Or, it can be logged from website clickstreams and process in near-real-time.
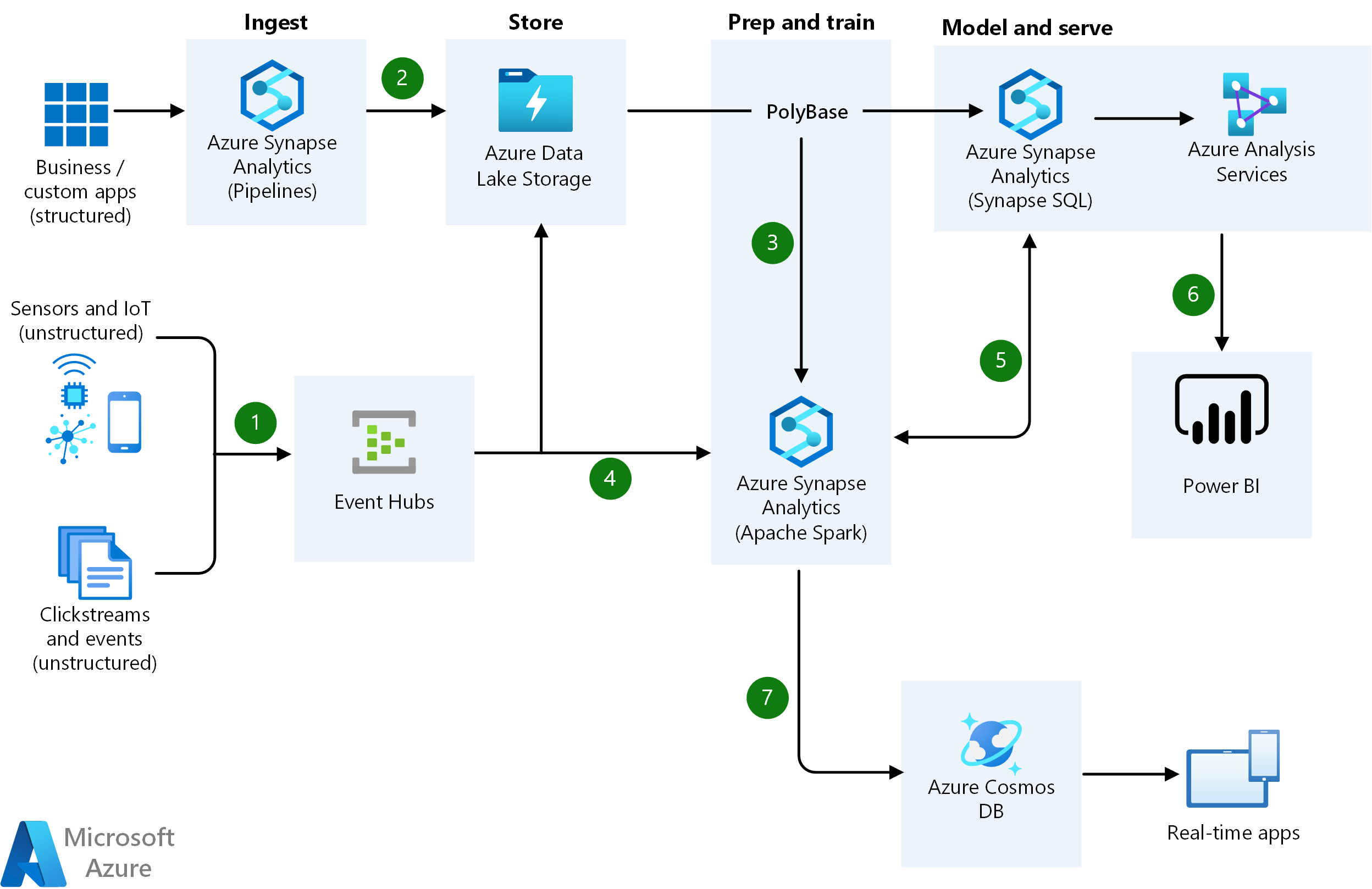
Data Flow:
- Firstly, easily ingesting live streaming data for an application using Azure Event Hubs.
- Secondly, using Synapse Pipelines to Azure Blob Storage for bringing together all your structured data.
- Thirdly, taking advantage of Apache Spark pools for cleaning, transforming, and analyzing the streaming data. And, combining it with structured data from operational databases or data warehouses.
- Fourthly, using Python, R, or Scala, with notebook experiences in Apache Spark pools to provide scalable machine learning/deep learning techniques for deriving deeper insights from this data.
- Then, supporting Apache Spark pool and Synapse Pipelines in Azure Synapse Analytics for accessing and moving data at scale.
- After that, building analytics dashboards and embedded reports in a dedicated SQL pool for sharing insights within your organization and using Azure Analysis Services to serve this data to thousands of users.
- Then, power users taking advantage of the capabilities of Apache Spark pools and Azure Event Hubs for performing root cause raw data analysis.
- Lastly, taking the insights from Apache Spark pools to Cosmos DB to make them accessible through real-time apps.
2. Advanced Analytics Architecture
Use the best machine learning tools for transforming your data into actionable insights. However, you can use this architecture for combining data at any scale. Furthermore, you can also create and deploy custom machine learning models at scale.

Data Flow:
- Firstly, bringing together all your structured, unstructured, and semi-structured data using Synapse Pipelines to Azure Data Lake Storage.
- Secondly, using Apache Spark pools for cleaning and transforming the structureless datasets and then, combining them with structured data from operational databases or data warehouses.
- Thirdly, using Python, R, or Scala, with notebook experiences in Apache Spark pools to provide scalable machine learning/deep learning techniques for deriving deeper insights from this data.
- Fourthly, supporting Apache Spark pool and Synapse Pipelines in Azure Synapse Analytics for accessing and moving data at scale.
- Then, power users taking advantage of the capabilities of Apache Spark pools for performing root cause determination and raw data analysis.
- Querying and reporting on data in Power BI.
- Lastly, taking the insights from Apache Spark pools to Cosmos DB for making them accessible through web and mobile apps.
3. Machine learning lifecycle management
This is for accelerating and managing end-to-end machine learning lifecycle with Azure Databricks, MLflow, and Azure Machine Learning for building, sharing, deploying, and managing machine learning applications.
However, in this, the supported capabilities include:
- Firstly, tracking and logging experiment metrics and artifacts in your Azure Machine Learning workspace.
- Secondly, submitting training jobs with MLflow Projects with Azure Machine Learning backend support.
- Lastly, tracking and managing models in MLflow and Azure Machine Learning model registry.
MLflow Tracking, track an experiment’s run metrics and store model artifacts in your Azure Machine Learning workspace.
Is Azure Databricks secure? The Answer is Yes! Check the below points to clear your doubt.
Data security and privacy
- Azure Databricks is for securing, monitoring, and managing data and analytics solutions with a large range of leading security and compliance features.
- Secondly, it has single sign-on and Azure Active Directory integration for enabling data professionals to spend more time discovering insights.
- Lastly, Azure has more certifications than any other cloud provider. It offers a comprehensive list.
Moving on, in the upcoming sections, we will understand the services and products that Azure Databricks offers. This will provide us clarity bout the functioning of Databricks in Azure.
Azure Databricks: Products & Services

1. Azure Data Factory
Azure Data Factory is a serverless data integration solution for ingesting, preparing, and transforming data at scale. This provides data source visual integration with more than 90 built-in, maintenance-free connectors at no cost. Moreover, in this, you can construct ETL and ELT processes code-free in an intuitive environment or write your own code. Then, deliver integrated data to Azure Synapse Analytics for unlocking business insights.
Features:
- Firstly, it easy-to-use as you can rehost SQL Server Integration Services (SSIS) in a few clicks and build ETL and ELT pipelines code-free using built-in Git and CI/CD support.
- Secondly, it provides pay-as-you-go services that are fully manageable serverless cloud services.
- Thirdly, it uses autonomous ETL for unlocking operational efficiencies and enable citizen integrators.
- Next, Azure Data Factor provides data integration and transformation layer that works across your digital transformation initiatives.
- Lastly, it helps in rehosting and extending SSIS in a few clicks thus, helping organizations modernizing SSIS.
2. Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake for your high-performance analytics workloads. This removes data silos with a single storage platform. Moreover, it optimizes costs with tiered storage and policy management. And, it uses Azure Active Directory and role-based access control for authenticating data. Further, it helps in protecting data with security features like encryption at rest and advanced threat protection.
Features:
- Firstly, it offers limitless scaling and 16 9s of data durability with automatic geo-replication. You can meet any capacity requirements and manage data using the Azure global infrastructure. Moreover, run large-scale analytics queries with high performance.
- Secondly, it provides highly secure with flexible mechanisms for protection across data access, encryption, and network-level control.
- Thirdly, it offers a single storage platform for ingestion, processing, and visualization that supports the most common analytics frameworks.
- Next, Azure Data Lake Storage helps in building cost-effective data lakes. As it optimizes costs by scaling storage and compute independently. Optimize storage costs using automated lifecycle management policies.
- Lastly, it helps in building a scalable foundation for your analytics. It ingests data at scale using a wide range of data ingestion tools and then, uses Azure Databricks, Synapse Analytics, or HDInsight for processing data.
3. Azure Machine Learning
This provides an enterprise-grade machine learning service for building and deploying models faster. It authorizes data scientists and developers with a wide range of productive experiences for building, training, and deploying machine learning models as well as for encouraging team collaboration. Moreover, this accelerates time for marketing with industry-leading MLOp.
Features:
- Firstly, it rapidly builds and deploys machine learning models using tools that meet your needs regardless of skill level. You can use built-in Jupyter Notebooks with Intellisense or the drag-and-drop designer. Moreover, it, accelerate model creation with automated machine learning and access powerful feature engineering, algorithm selection, and hyperparameter-sweeping capabilities. And, increasing team efficiency using notebooks, models, shared datasets, and customizable dashboards for tracking the machine learning process.
- Secondly, it provides robust MLOps capabilities that enable the creation and deployment of models at scale using automated and reproducible machine learning workflows. Use MLOps for streamlining the machine learning lifecycle, from building models to deployment and management. Moreover, creating reproducible workflows with machine learning pipelines including training, validating, and deploying thousands of models at scale, from the cloud to the edge.
- Thirdly, it builds responsible machine learning solutions. It provides access to state-of-the-art responsible machine learning capabilities for understanding, protecting, and controlling your data, models, and processes. Moreover, it preserves data privacy throughout the machine learning lifecycle with differential privacy techniques and uses confidential computing to secure machine learning assets.
- Lastly, it is best-in-class support for open-source frameworks and languages including MLflow, Kubeflow, ONNX, PyTorch, TensorFlow, Python, and R.
4. Power BI Embedded
This adds analytics and interactive reporting to your applications. Moreover, Power BI provides customer-facing reports, dashboards, and analytics in your own applications. Further, it reduces developer resources by automating the monitoring, management, and deployment of analytics, while getting full control of Power BI features and intelligent analytics.
Features:
- Firstly, it modifies decades of analytics expertise and accesses to the continued investment Microsoft makes in analytics and AI.
- Secondly, you will get to choose the best way for visualizing your data with out-of-the-box, certified, and custom-built visuals
- Thirdly, users can take decisions anywhere using the visualizations optimized for desktop and mobile.
- Next, it is cost-efficient. Moreover, it provides interactive reports and dashboards into your applications for standing out from the competition.
- Lastly, using Power BI Embedded APIs, SDKs, and wizards, it becomes easy to prepare the development environment to deploy analytics in your application.
Above we have understood the functionalities and services for the Azure Databricks. Now, I think we are ready to get started with the Azure Databricks. So, without wasting let’s get started with it.
Getting started with Azure Databricks
 Firstly, sign up for an Azure free account to get instant access.
Firstly, sign up for an Azure free account to get instant access.
 Secondly, go through the documentation provided for Azure Databricks.
Secondly, go through the documentation provided for Azure Databricks.
 Thirdly, explore the quickstart for creating a cluster, notebook, table, and more.
Thirdly, explore the quickstart for creating a cluster, notebook, table, and more.
Click here! for Azure Databricks pricing details.
Create an Azure Databricks workspace
In this section, we will learn about creating an Azure Databricks workspace using the Azure portal or the Azure CLI. Let’s take a look at the Azure Portal example.
Azure Portal
- Firstly, in the Azure portal, select Create a resource and then choose Analytics. Then, select, Azure Databricks.
- Secondly, provide the values for creating a Databricks workspace under Azure Databricks Service.
- Provide the following values:
- Workspace name
- Provide a name for your Databricks workspace
- Subscription
- From the drop-down, select your Azure subscription.
- Resource group
- Specify whether you want to create a new resource group or use an existing one. A resource group refers to a container holding related resources for an Azure solution.
- Location
- Select West US 2.
- Pricing Tier
- Choose between Standard, Premium, or Trial.
- Workspace name
- Lastly, select Review + Create, and then Create. However, the workspace creation will take few minutes. During workspace creation, you can check the deployment status in Notifications. After completing the process, your user account is automatically added as an admin user in the workspace.
If, workspace deployment fails, then, the workspace is still created in a failed state. However, deleting the failed workspace and creating a new workspace that resolves the deployment errors. Further, when you delete the failed workspace, then, the managed resource group and successfully deployed resources are also deleted.
Create a Spark cluster in Databricks
- Firstly, go to the Databricks workspace that you created in the Azure Portal. Then, click Launch Workspace.
- Now, you will be redirected to the Azure Databricks portal. Then, from the portal, click New Cluster.
- Thirdly, provide the values for creating a cluster on the New cluster page.
- Then, accept all other default values other than the following:
- Firstly, enter a name for the cluster.
- Secondly, create a cluster with (5.X, 6.X, 7.X) runtime.
- Thirdly, make sure to select the Terminate after __ minutes of inactivity checkbox. Then, provide a duration (in minutes) for terminating the cluster, if the cluster is not being used.
- Lastly, select Create cluster. After the cluster starts running, you can attach notebooks to the cluster and run Spark jobs.
Final Words
Above we learned about the Azure Databricks and hows its Apache Spark-based analytics services are providing benefits to many organizations. Using the Azure Databricks SQL Analytics and Azure Databricks Workspace, it has become easy to manage any kind of data. So, go through the article to gain an understanding of the services and explore the documentation for getting started with Databricks. I hope the above information will help you in starting your journey in the Azure Databricks.
