Identify the Appropriate Data Processing Technology for a given scenario
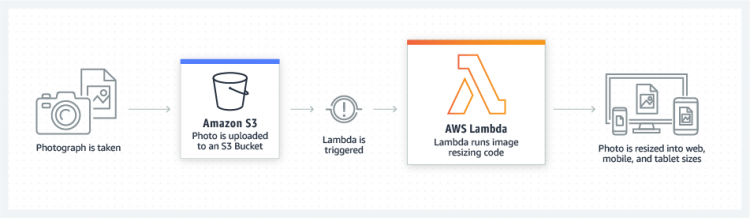
Real-time file processing
- Use S3 to trigger AWS Lambda to process data immediately after an upload.
- Real-time processing examples
- thumbnail images
- transcode videos
- index files
- process logs
- validate content
- aggregate and filter data in real-time.
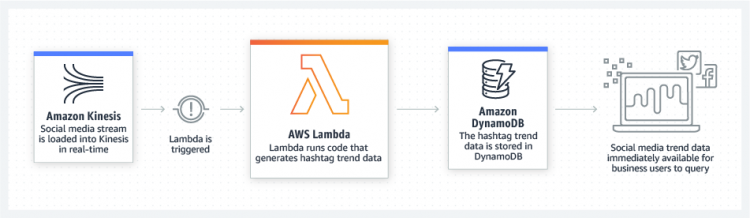
Real-time stream processing
- Use AWS Lambda and Amazon Kinesis to process real-time streaming data
- Real-time streaming data example
- application activity tracking
- transaction order processing
- click stream analysis
- data cleansing
- metrics generation
- log filtering
- indexing
- social media analysis
- IoT device data telemetry and metering.
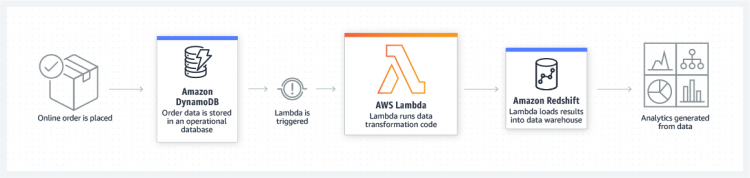
Extract, transform, load
- Lambda to perform ETL, as
- data validation
- filtering
- sorting
- other transformations for every data change in a DynamoDB table
- load the transformed data to another data store.
IoT backends
- Build serverless backends with Lambda
- Manage
- Web applications
- Mobile applications
- Internet of Things (IoT)
- 3rd party API requests
Mobile backends
- Build Mobile backends to create rich, personalized app experiences
- Lambda and Amazon API Gateway to
- authenticate and process API requests
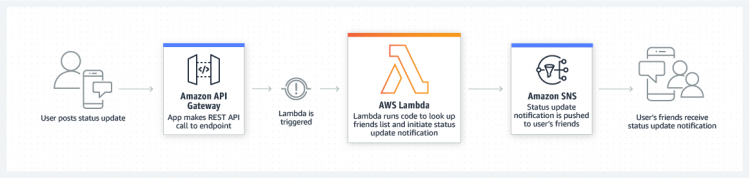
Web Applications
- Build powerful web applications with Lambda
- Applications can
- automatically scale up and down
- run in a highly available configuration
- zero administrative effort.
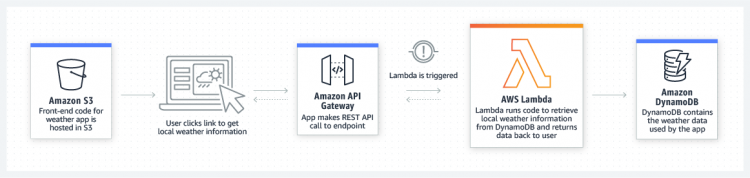
AWS Lambda
- It is a compute service
- Runs code without provisioning or managing servers.
- It executes code only when needed and scales automatically
- Upload code and Lambda takes care of everything.
- Set up code to automatically trigger from other AWS services
- Call Code directly from any web or mobile app.
- Code can be executed against triggers – changes in data, shifts in system state, or actions by users. Direct trigger from AWS services – S3, DynamoDB, Kinesis, SNS, and CloudWatch
- Trigger can be orchestrated into workflows by AWS Step Functions.
- Can build a variety of real-time serverless data processing systems.
- Customer is responsible only for code.
- Lambda manages the memory, CPU, network, and other resources.
- You cannot log in to compute instances, or customize the operating system or language runtime.
Lambda Working
- Lambda runs functions in a serverless environment to process events.
- Each instance of function runs in an isolated execution context
- one event at a time is processed.
- After finishing event processing, a response is returned and Lambda sends it another event.
Lambda Components
- Function – A script or program that runs in AWS Lambda. Lambda passes invocation events to function. The function processes an event and returns a response.
- Runtimes – Lambda runtimes allow functions in different languages to run in the same base execution environment. You configure function to use a runtime that matches programming language. The runtime sits in-between the Lambda service and function code, relaying invocation events, context information, and responses between the two. You can use runtimes provided by Lambda, or build own.
- Layers – Lambda layers are a distribution mechanism for libraries, custom runtimes, and other function dependencies. Layers let you manage in-development function code independently from the unchanging code and resources that it uses. You can configure function to use layers that you create, layers provided by AWS, or layers from other AWS customers.
- Event source – An AWS service, such as Amazon SNS, or a custom service, that triggers function and executes its logic.
- Downstream resources – An AWS service, such as DynamoDB tables or Amazon S3 buckets, that Lambda function calls once it is triggered.
- Log streams –Lambda monitors function invocations and reports metrics to CloudWatch. Annotate function code with custom logging statements to analyze the execution flow and performance of Lambda function to ensure it’s working properly.
- AWS SAM – A model to define serverless applications. AWS SAM is natively supported by AWS CloudFormation and defines simplified syntax for expressing serverless resources.
Lambda function configuration, deployments, and execution limits
| Resource | Limit |
| Function memory allocation | 128 MB to 3,008 MB, in 64 MB increments. |
| Function timeout | 900 seconds (15 minutes) |
| Function environment variables | 4 KB |
| Function resource-based policy | 20 KB |
| Function layers | 5 layers |
| Invocation frequency (requests per second) | 10 x concurrent executions limit (synchronous – all sources) 10 x concurrent executions limit (asynchronous – non-AWS sources) Unlimited (asynchronous – AWS service sources) |
| Invocation payload (request and response) | 6 MB (synchronous) 256 KB (asynchronous) |
| Deployment package size | 50 MB (zipped, for direct upload) 250 MB (unzipped, including layers) 3 MB (console editor) |
| Test events (console editor) | 10 |
/tmp directory storage | 512 MB |
| File descriptors | 1,024 |
| Execution processes/threads | 1,024 |
AWS Lambda-based application lifecycle
- authoring code
- deploying code to AWS Lambda
- monitoring and troubleshooting
AWS Lambda supported languages, their tools and options
| Language | Tools and Options for Authoring Code |
| Node.js | AWS Lambda consoleVisual Studio, with IDE plug-in own authoring environment |
| Java | Eclipse, with AWS Toolkit for Eclipse IntelliJ, with the AWS Toolkit for IntelliJown authoring environment |
| C# | Visual Studio, with IDE plug-in .NET Core own authoring environment |
| Python | AWS Lambda consolePyCharm, with the AWS Toolkit for PyCharmown authoring environment |
| Ruby | AWS Lambda consoleown authoring environment |
| Go | own authoring environment |
| PowerShell | own authoring environmentPowerShell Core 6.0 .NET Core 2.1 SDK AWSLambdaPSCore Module |
AWS Glue
- It is a fully managed ETL (extract, transform, and load) service
- Simple and cost-effective to
- categorize data
- clean it
- enrich it
- move it reliably between various data stores.
- It consists of a central metadata repository – AWS Glue Data Catalog
- Data Catalog is
- an ETL engine
- automatically generates Python or Scala code
- a flexible scheduler
- handles dependency resolution, job monitoring, and retries.
- AWS Glue is serverless, so no infrastructure to set up or manage.
- Use the AWS Glue console to discover data and transform it
- Console can also call services to orchestrate the work required
- Also use AWS Glue API operations to interface with AWS Glue services.
- Edit, debug, and test Python or Scala code
- Apache Spark ETL code using a familiar development environment.
AWS Glue as a data warehouse:
- Discovers and catalogs metadata about data stores into a central catalog.
- Can also process semi-structured data, such as clickstream or process logs.
- Populates with table definitions from scheduled crawler programs.
- Generates ETL scripts to transform, flatten, and enrich data from source to target.
- Detects schema changes and adapts based on preferences.
- Triggers ETL jobs based on a schedule or event.
- Triggers can be used to create a dependency flow between jobs.
- Gathers runtime metrics to monitor the activities of data warehouse.
- Handles errors and retries automatically.
- Scales resources, as needed, to run jobs.
- Define jobs in AWS Glue to accomplish the work
AWS Glue typical actions
- Define a crawler to populate Glue Data Catalog with metadata table definitions. Point crawler at a data store, and the crawler creates table definitions in the Data Catalog.
- Glue Data Catalog can contain other metadata to define ETL jobs.
- It can generate a script to transform data. Or, provide your script in Glue console or API.
- Run job on demand, or start when a specified trigger occurs.
- The trigger can be a time-based schedule or an event.
- When job runs, a script extracts data from data source, transforms the data, and loads it to data target.
- The script runs in an Apache Spark environment in AWS Glue.
AWS Glue Components
- AWS Glue Data Catalog – The persistent metadata store in AWS Glue. Each AWS account has one AWS Glue Data Catalog. It contains table definitions, job definitions, and other control information to manage AWS Glue environment.
- Classifier – Determines the schema of data. AWS Glue provides classifiers for common file types, such as CSV, JSON, AVRO, XML, and others. It also provides classifiers for common relational database management systems using a JDBC connection. You can write own classifier by using a grok pattern or by specifying a row tag in an XML document.
- Connection – Contains the properties that are required to connect to data store.
- Crawler – A program that connects to a data store (source or target), progresses through a prioritized list of classifiers to determine the schema for data, and then creates metadata in the AWS Glue Data Catalog.
- Database – A set of associated table definitions organized into a logical group in AWS Glue.
- Data store, data source, data target – A data store is a repository for persistently storing data. Examples include Amazon S3 buckets and relational databases. A data source is a data store that is used as input to a process or transform. A data target is a data store that a process or transform writes to.
- Development endpoint – An environment that you can use to develop and test AWS Glue scripts.
- Job – The business logic that is required to perform ETL work. It is composed of a transformation script, data sources, and data targets. Job runs are initiated by triggers that can be scheduled or triggered by events.
- Notebook server – A web-based environment that you can use to run PySpark statements.
- Script – Code that extracts data from sources, transforms it, and loads it into targets. AWS Glue generates PySpark or Scala scripts.
- Table – It defines the schema of data. Data may be S3 file, an RDS table, or another set of data. It consists of names of columns, data type definitions, and other metadata about a base dataset. The schema of data is represented in AWS Glue table definition. The actual data remains in its original data store, whether it be in a file or a relational database table. AWS Glue catalogs files and relational database tables in the AWS Glue Data Catalog. They are used as sources and targets when you create an ETL job.
- Transform – The code logic that is used to manipulate data into a different format.
- Trigger – Initiates an ETL job. Triggers can be defined based on a scheduled time or an event.
Amazon EMR
- It is a managed cluster platform
- Simplifies running big data frameworks – Apache Hadoop and Apache Spark on AWS
- Process and analyze vast amounts of data.
- Uses Apache Hive and Apache Pig, to process data for analytics and BI.
- Use to transform and move large amounts of data into and out of other AWS data stores and databases.
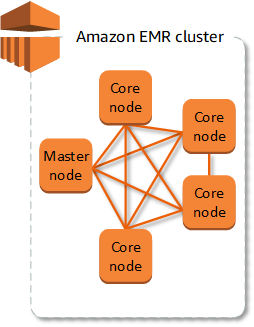
EMR Cluster
- The central component is the cluster.
- A cluster is a collection of Amazon EC2 instances.
- Each instance in the cluster is called a node. Each node has a role within the cluster, referred to as the node type. Amazon EMR also installs different software components on each node type, giving each node a role in a distributed application like Apache Hadoop.
EMR node types
- Master node: It manages the cluster to coordinate the distribution of data and tasks among other nodes for processing. It tracks status of tasks and monitors the health of the cluster. Every cluster has a master node and a single-node cluster has only the master node.
- Core node: Run tasks and store data in Hadoop Distributed File System (HDFS) on cluster. Multi-node clusters have at least one core node.
- Task node: Only runs tasks and does not store data in HDFS. Task nodes are optional.
Diagram of an EMR cluster with one master node and four core nodes.
Options to complete the tasks can be specified Amazon EMR, as
- Provide the entire definition of the work to be done in functions, specified as steps when cluster is created. It is for clusters processing a set amount of data and then terminate after process completion.
- Create a long-running cluster and use the Amazon EMR console, the Amazon EMR API, or the AWS CLI to submit steps, which may contain one or more jobs.
- Create a cluster, connect to the master node and other nodes as required using SSH, and use the interfaces that the installed applications provide to perform tasks and submit queries, either scripted or interactively.
Data Processing in EMR
- Select the frameworks and applications to install during cluster launch
- To process data in cluster
- submit jobs or queries directly to installed applications
- or run steps in the cluster.
- During processing, input is data stored as files in S3 or HDFS.
- This data passes from one step to the next in the processing sequence.
- The final step writes the output data to a specified location, like Amazon S3 bucket.
Steps are run in the following sequence:
- A request is submitted to begin processing steps.
- The state of all steps is set to PENDING.
- When the first step in the sequence starts, its state changes to RUNNING. The other steps remain in the PENDING state.
- After the first step completes, its state changes to COMPLETED.
- The next step in the sequence starts, and its state changes to RUNNING. When it completes, its state changes to COMPLETED.
- This pattern repeats for each step until they all complete and processing ends.
- If a step fails during processing, its state changes to TERMINATED_WITH_ERRORS.
- You can determine what happens next for each step.
- By default, any remaining steps in the sequence are set to CANCELLED and do not run.
- You can choose to ignore the failure and allow remaining steps to proceed, or to terminate the cluster immediately.
The diagram shows the step sequence and change of state
