Disaster Recovery
- It is about preparing for and recovering from a disaster.
- Any event that has a negative impact on a company’s business continuity or finances is a disaster.
- Also includes
- hardware or software failure
- a network outage
- a power outage
- physical damage to a building like fire or flooding
- human error
- or some other significant event.
- Traditionally companies duplicate or increase capacities for DR
- Critical metric for backup, are
- RPO – maximum period of data loss, acceptable in failure or incident.
- RTO – maximum amount of downtime, permitted to recover from backup and resume processing.
AWS Services for DR (Disaster Recovery)
Regions
AWS are in multiple regions around the globe, choose most appropriate location for data and DR
Storage
Amazon S3
- Objects are redundantly stored on multiple devices across multiple facilities within a region
- designed to provide a durability of 99.999999999% (11 9s).
- protection for data retention and archiving through versioning in Amazon S3,
- AWS multi-factor authentication (AWS MFA)
- bucket policies
- Identity and Access Management (IAM).
Amazon Glacier
- extremely low-cost storage for data archiving and backup.
- Objects (or archives, as they are known in Amazon Glacier) are optimized for infrequent access,
- retrieval times of several hours.
- Glacier has same durability as Amazon S3.
Amazon EBS
- Can create point-in-time snapshots of data volumes.
- use snapshots as starting point for new EBS volumes
- long-term durability as snapshots are stored within S3.
- After a volume is created, attach it to a running EC2 instance.
- Amazon EBS volumes persists independently from life of instance and is replicated across multiple servers in AZ
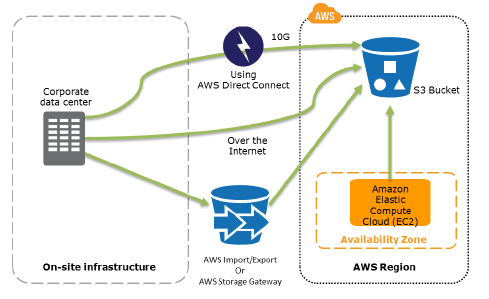
AWS Storage Gateway
- service to connect an on-premises software appliance with cloud-based storage
- provides seamless and highly secure integration between on-premises and AWS
Compute
Amazon EC2
- provides resizable compute capacity in the cloud.
- Within minutes, create EC2 instances or virtual machines with complete control.
- For DR, rapidly create virtual machines to control is critical.
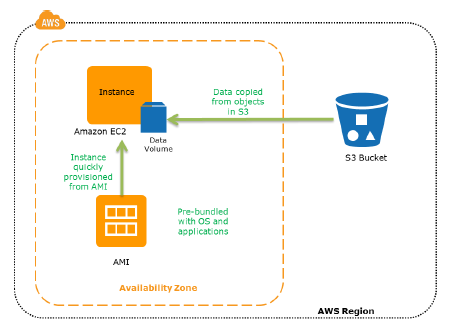
AMIs
- are preconfigured with operating systems
- might also include application stacks.
- can also configure own AMIs.
- For DR, configure and identify own AMIs to launch during recovery procedure.
Availability Zones
- are distinct locations insulated from failures in other AZ
- provide inexpensive, low-latency network connectivity to other AZ in same region.
- With instances in separate AZ protect applications from failure of a single location.
- Regions consist of one or more Availability Zones.
Networking
Amazon Route 53
- a highly available and scalable DNS web service.
- a reliable, cost-effective way to route users to Internet applications.
- Route 53 has global load-balancing capabilities
- ability to failover between multiple endpoints and even static websites hosted in Amazon S3.
Elastic IP addresses
- static IP addresses designed for dynamic cloud computing
- Elastic IP addresses can mask instance or AZ failures by
- Can pre-allocate some IP addresses for most critical systems hence, IP addresses are known before disaster strikes.
- simplifying execution of the DR plan.
Elastic Load Balancing
- automatically distributes incoming application traffic across multiple Amazon EC2 instances.
- Provides fault tolerance in applications
- Provide load-balancing capacity as per incoming application traffic.
- can pre-allocate load balancer
Amazon VPC
- provision a private, isolated section of the AWS cloud
- can launch AWS resources in a virtual network that you define.
- Gives complete control over virtual networking environment including
- selection of own IP address range
- creation of subnets
- configuration of route tables and network gateways.
Amazon Direct Connect
- set up a dedicated network connection from premises to AWS.
Databases
Amazon RDS
- easily to set up, operate, and scale a relational database
- gives ability to snapshot data from one region to another
- Can have a read replica running in another region.
Amazon DynamoDB
- a fast, fully managed NoSQL database service
- has reliable throughput and single-digit, millisecond latency.
- Can copy data to DynamoDB in another region or to Amazon S3.
- In DR recovery scale up seamlessly with a single click or API call.
Amazon Redshift
- is a fast, fully managed, petabyte-scale data warehouse service
- Use it in DR preparation phase to snapshot data warehouse to S3
- In DR recovery quickly restore data warehouse into the same region or within another AWS region.
- install and run choice of database software
Backup and restore
Key steps for backup and restore
- Select an appropriate tool or method to back up data into AWS.
- Ensure that you have an appropriate retention policy for this data.
- Ensure that appropriate security measures are in place for this data, including encryption and access policies.
- Regularly test the recovery of this data and restoration of system.
- Data backup options to S3 from on-site infrastructure, or from AWS –
Restoring a system from S3 backups to AWS EC2 –