Determine the Operational Characteristics of the Collection System
AWS Big Data Exam updated to AWS Certified Data Analytics Specialty.
Big Data 4Vs or features
- Volume – It is related to enormous size.
- Variety – It is the heterogeneous sources and the nature of data, both structured and unstructured. It can be emails, photos, videos, monitoring devices, PDFs, audio, etc. for analysis.
- Velocity – It is the speed of generation of data or speed at which data flows in from sources though the flow of data is massive and continuous.
- Variability – It refers to the inconsistency in the data .
Characteristics of data collection
- Validity is the degree to which the tool measures what it is intended to measure. Weighing scale measures body weight and its valid; a tool which is valid for one measure, need not be valid for another.
- Reliability indicates the accuracy and consistency of input data.
- Sensitivity refers to the capability to detect changes or difference when they to occur.
- Objectivity means freedom from bias.
- Economy: Cost and resource needed
- Practicability: Simplicity of administration, scoring and interpretations.
Stream Processing
Streaming Data is data that is generated continuously by thousands of data sources, which typically send in the data records simultaneously, and in small sizes (order of Kilobytes). Streaming data includes a wide variety of data such as log files generated by customers using your mobile or web applications, ecommerce purchases, in-game player activity, information from social networks, financial trading floors, or geospatial services, and telemetry from connected devices or instrumentation in data centers.
| Batch processing | Stream processing | |
| Data scope | Queries or processing over all or most of the data in the dataset. | Queries or processing over data within a rolling time window, or on just the most recent data record. |
| Data size |
Large batches of data. | Individual records or micro batches consisting of a few records. |
| Performance | Latencies in minutes to hours. | Requires latency in the order of seconds or milliseconds. |
| Analyses | Complex analytics. | Simple response functions, aggregates, and rolling metrics. |
Stream Processing Challenges – Processing real-time data as it arrives can enable you to make decisions much faster than is possible with traditional data analytics technologies. However, building and operating your own custom streaming data pipelines is complicated and resource intensive. You have to build a system that can cost-effectively collect, prepare, and transmit data coming simultaneously from thousands of data sources. You need to fine-tune the storage and compute resources so that data is batched and transmitted efficiently for maximum throughput and low latency. You have to deploy and manage a fleet of servers to scale the system so you can handle the varying speeds of data you are going to throw at it. After you have built this platform, you have to monitor the system and recover from any server or network failures by catching up on data processing from the appropriate point in the stream, without creating duplicate data. All of this takes valuable time and money and, at the end of the day, most companies just never get there and must settle for the status-quo and operate their business with information that is hours or days old.
AWS Services for Collection of Different Data Types
Real Time – Immediate actions
- Kinesis Data Streams (KDS)
- Simple Queue Service (SQS)
- Internet of Things (IoT)
Near-real time – Reactive actions
- Kinesis Data Firehose (KDF)
- Database Migration Service (DMS)
Batch – Historical Analysis
- Snowball
- Data Pipeline
Amazon Kinesis
Use Amazon Kinesis Data Streams to collect and process large streams of data records in real time. You can create data-processing applications, known as Kinesis Data Streams applications. A typical Kinesis Data Streams application reads data from a data stream as data records.
You can use Kinesis Data Streams for rapid and continuous data intake and aggregation. The type of data used can include IT infrastructure log data, application logs, social media, market data feeds, and web clickstream data. Because the response time for the data intake and processing is in real time, the processing is typically lightweight.
The following diagram illustrates the high-level architecture of Kinesis Data Streams. The producers continually push data to Kinesis Data Streams, and the consumers process the data in real time. Consumers (such as a custom application running on Amazon EC2 or an Amazon Kinesis Data Firehose delivery stream) can store their results using an AWS service such as Amazon DynamoDB, Amazon Redshift, or Amazon S3.
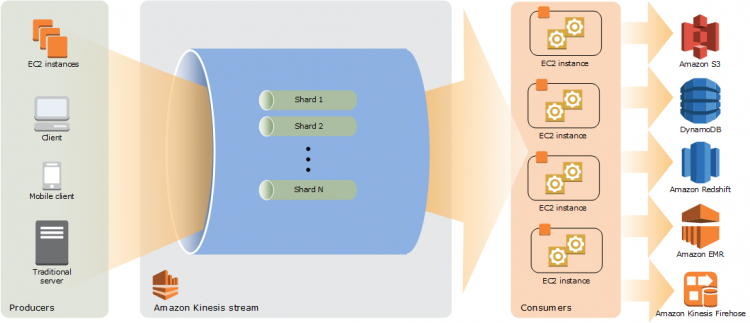
Benefits
- Real-time – Amazon Kinesis enables you to ingest, buffer, and process streaming data in real-time, so you can derive insights in seconds or minutes instead of hours or days.
- Fully managed – Amazon Kinesis is fully managed and runs your streaming applications without requiring you to manage any infrastructure.
- Scalable – Amazon Kinesis can handle any amount of streaming data and process data from hundreds of thousands of sources with very low latencies.
Kinesis Data Streams Terminology
- Kinesis Data Stream – A Kinesis data stream is a set of shards. Each shard has a sequence of data records. Each data record has a sequence number that is assigned by Kinesis Data Streams.
- Data Record – A data record is the unit of data stored in a Kinesis data stream. Data records are composed of a sequence number, a partition key, and a data blob, which is an immutable sequence of bytes. Kinesis Data Streams does not inspect, interpret, or change the data in the blob in any way. A data blob can be up to 1 MB.
- Retention Period – The retention period is the length of time that data records are accessible after they are added to the stream. A stream’s retention period is set to a default of 24 hours after creation. You can increase the retention period up to 168 hours (7 days) using the IncreaseStreamRetentionPeriod operation, and decrease the retention period down to a minimum of 24 hours using the DecreaseStreamRetentionPeriod operation. Additional charges apply for streams with a retention period set to more than 24 hours.
- Producer – Producers put records into Amazon Kinesis Data Streams. For example, a web server sending log data to a stream is a producer.
- Consumer – Consumers get records from Amazon Kinesis Data Streams and process them. These consumers are known as Amazon Kinesis Data Streams Application.
- Amazon Kinesis Data Streams Application – An Amazon Kinesis Data Streams application is a consumer of a stream that commonly runs on a fleet of EC2 instances. There are two types of consumers that you can develop: shared fan-out consumers and enhanced fan-out consumers.
- Shard – A shard is a uniquely identified sequence of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity. Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys). The data capacity of your stream is a function of the number of shards that you specify for the stream. The total capacity of the stream is the sum of the capacities of its shards.
- Partition Key – A partition key is used to group data by shard within a stream. Kinesis Data Streams segregates the data records belonging to a stream into multiple shards. It uses the partition key that is associated with each data record to determine which shard a given data record belongs to. Partition keys are Unicode strings with a maximum length limit of 256 bytes. An MD5 hash function is used to map partition keys to 128-bit integer values and to map associated data records to shards. When an application puts data into a stream, it must specify a partition key.
- Sequence Number – Each data record has a sequence number that is unique per partition-key within its shard. Kinesis Data Streams assigns the sequence number after you write to the stream with client.putRecords or client.putRecord. Sequence numbers for the same partition key generally increase over time. The longer the time period between write requests, the larger the sequence numbers become.
- Kinesis Client Library – The Kinesis Client Library is compiled into your application to enable fault-tolerant consumption of data from the stream. The Kinesis Client Library ensures that for every shard there is a record processor running and processing that shard. The library also simplifies reading data from the stream. The Kinesis Client Library uses an Amazon DynamoDB table to store control data. It creates one table per application that is processing data.
AWS Kinesis Summary
- The unit of data stored by Kinesis Data Streams is a data record. A stream represents a group of data records. The data records in a stream are distributed into shards.
- A shard has a sequence of data records in a stream. When you create a stream, you specify the number of shards for the stream. Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second. Shards also support up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys). The total capacity of a stream is the sum of the capacities of its shards. You can increase or decrease the number of shards in a stream as needed. However, you are charged on a per-shard basis. Billing is per shard provisioned, can have as many shards as you want. Records are ordered per shard.
- The unit of data of the Kinesis data stream, which is composed of a sequence number (The unique identifier of the record within its shard. Type: String), a partition key (Identifies which shard in the stream the data record is assigned to. Type: String ), and a data blob(The data in the blob is both opaque and immutable to Kinesis Data Streams, which does not inspect, interpret, or change the data in the blob in any way. When the data blob, the payload before base64-encoding, is added to the partition key size, the total size must not exceed the maximum record size of 1 MB. Type: Base64-encoded binary data object).
- If you have sensitive data, you can enable server-side data encryption when you use Amazon Kinesis Data Firehose. However, this is only possible if you use a Kinesis stream as your data source. When you configure a Kinesis stream as the data source of a Kinesis Data Firehose delivery stream, Kinesis Data Firehose no longer stores the data at rest. Instead, the data is stored in the Kinesis stream.
- When you send data from your data producers to your Kinesis stream, the Kinesis Data Streams service encrypts your data using an AWS KMS key before storing it at rest. When your Kinesis Data Firehose delivery stream reads the data from your Kinesis stream, the Kinesis Data Streams service first decrypts the data and then sends it to Kinesis Data Firehose. Kinesis Data Firehose buffers the data in memory based on the buffering hints that you specify and then delivers it to your destinations without storing the unencrypted data at rest.
- In Kinesis , to prevent skipped records, handle all exceptions within processRecords appropriately.
- For each Amazon Kinesis Data Streams application, the KCL uses a unique Amazon DynamoDB table to keep track of the application’s state. Because the KCL uses the name of the Amazon Kinesis Data Streams application to create the name of the table, each application name must be unique.
- If your Amazon Kinesis Data Streams application receives provisioned-throughput exceptions, you should increase the provisioned throughput for the DynamoDB table. The KCL creates the table with a provisioned throughput of 10 reads per second and 10 writes per second, but this might not be sufficient for your application. For example, if your Amazon Kinesis Data Streams application does frequent checkpointing or operates on a stream that is composed of many shards, you might need more throughput.
- PutRecord returns the shard ID of where the data record was placed and the sequence number that was assigned to the data record. Sequence numbers increase over time and are specific to a shard within a stream, not across all shards within a stream. To guarantee strictly increasing ordering, write serially to a shard and use the SequenceNumberForOrdering parameter.
- For live streaming Kinesis gets ruled out if record size greater than 1 MB , in that case Kafka can support bigger records.
- You can trigger One lambda per shard. If you want to use Lambda with Kinesis Streams, you need to create Lambda functions to automatically read batches of records off your Amazon Kinesis stream and process them if records are detected on the stream. AWS Lambda then polls the stream periodically (once per second) for new records.
- In Kinesis stream ,the PutRecordBatch() operation can take up to 500 records per call or 4 MB per call, whichever is smaller. Buffer size ranges from 1 MB to 128 MB.
- In circumstances where data delivery to the destination is falling behind data ingestion into the delivery stream, Amazon Kinesis Firehose raises the buffer size automatically to catch up and make sure that all data is delivered to the destination.
- If data delivery to Redshift fail from Kinesis Firehose , Amazon Kinesis Firehose retries data delivery every 5 minutes for up to a maximum period of 60 minutes. After 60 minutes, Amazon Kinesis Firehose skips the current batch of S3 objects that are ready for COPY and moves on to the next batch. The information about the skipped objects is delivered to your S3 bucket as a manifest file in the errors folder, which you can use for manual backfill. For information about how to COPY data manually with manifest files, see Using a Manifest to Specify Data Files.
- If data delivery to your Amazon S3 bucket fails , Amazon Kinesis Firehose retries to deliver data every 5 seconds for up to a maximum period of 24 hours. If the issue continues beyond the 24-hour maximum retention period, it discards the data.
- Aggregation refers to the storage of multiple records in a Streams record. Aggregation allows customers to increase the number of records sent per API call, which effectively increases producer throughput. Aggregation Storing multiple records within a single Kinesis Data Streams record while Collection using the API operation PutRecords to send multiple Kinesis Data Streams records to one or more shards in your Kinesis data stream.You can first aggregate stream record and then send them to stream using collection putrecords() in multiple shard.
- Spark Streaming uses the Kinesis Client Library (KCL) to consume data from a Kinesis stream. KCL handles complex tasks like load balancing, failure recovery, and check-pointing
- Amazon Kinesis Data Streams has the following stream and shard limits.
- There is no upper limit on the number of shards you can have in a stream or account. It is common for a workload to have thousands of shards in a single stream.
- There is no upper limit on the number of streams you can have in an account.
- A single shard can ingest up to 1 MiB of data per second (including partition keys) or 1,000 records per second for writes. Similarly, if you scale your stream to 5,000 shards, the stream can ingest up to 5 GiB per second or 5 million records per second. If you need more ingest capacity, you can easily scale up the number of shards in the stream using the AWS Management Console or the UpdateShardCount API.
- The default shard limit is 500 shards for the following AWS Regions: US East (N. Virginia), US West (Oregon), and EU (Ireland). For all other Regions, the default shard limit is 200 shards.
- The maximum size of the data payload of a record before base64-encoding is up to 1 MiB.
- GetRecords can retrieve up to 10 MiB of data per call from a single shard, and up to 10,000 records per call. Each call to GetRecords is counted as one read transaction.
- Each shard can support up to five read transactions per second. Each read transaction can provide up to 10,000 records with an upper limit of 10 MiB per transaction.
- Each shard can support up to a maximum total data read rate of 2 MiB per second via GetRecords. If a call to GetRecords returns 10 MiB, subsequent calls made within the next 5 seconds throw an exception.
Creating a Stream in Amazon Kinesis
You can create a stream using the Kinesis Data Streams console, the Kinesis Data Streams API, or the AWS Command Line Interface (AWS CLI).
To create a data stream using the console
- Sign in to the AWS Management Console and open the Kinesis console at https://console.aws.amazon.com/kinesis.
- In the navigation bar, expand the Region selector and choose a Region.
- Choose Create data stream.
- On the Create Kinesis stream page, enter a name for your stream and the number of shards you need, and then click Create Kinesis stream.
- On the Kinesis streams page, your stream’s Status is Creating while the stream is being created. When the stream is ready to use, the Status changes to Active.
- Choose the name of your stream. The Stream Details page displays a summary of your stream configuration, along with monitoring information.
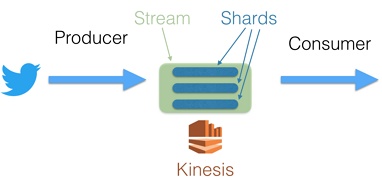
Kinesis Data Streams Producers
A producer puts data records into Amazon Kinesis data streams. For example, a web server sending log data to a Kinesis data stream is a producer. A consumer processes the data records from a stream.
To put data into the stream, you must specify the name of the stream, a partition key, and the data blob to be added to the stream. The partition key is used to determine which shard in the stream the data record is added to.
All the data in the shard is sent to the same worker that is processing the shard. Which partition key you use depends on your application logic. The number of partition keys should typically be much greater than the number of shards. This is because the partition key is used to determine how to map a data record to a particular shard. If you have enough partition keys, the data can be evenly distributed across the shards in a stream.
Using KPL – The KPL is an easy-to-use, highly configurable library that helps you write to a Kinesis data stream. It acts as an intermediary between your producer application code and the Kinesis Data Streams API actions. The KPL performs the following primary tasks:
- Writes to one or more Kinesis data streams with an automatic and configurable retry mechanism
- Collects records and uses PutRecords to write multiple records to multiple shards per request
- Aggregates user records to increase payload size and improve throughput
- Integrates seamlessly with the Kinesis Client Library (KCL) to de-aggregate batched records on the consumer
- Submits Amazon CloudWatch metrics on your behalf to provide visibility into producer performance
Using the Amazon Kinesis Data Streams API – You can develop producers using the Amazon Kinesis Data Streams API with the AWS SDK for Java. Once a stream is created, you can add data to it in the form of records. A record is a data structure that contains the data to be processed in the form of a data blob. After you store the data in the record, Kinesis Data Streams does not inspect, interpret, or change the data in any way. Each record also has an associated sequence number and partition key. There are two different operations in the Kinesis Data Streams API that add data to a stream, PutRecords and PutRecord. The PutRecords operation sends multiple records to your stream per HTTP request, and the singular PutRecord operation sends records to your stream one at a time (a separate HTTP request is required for each record). You should prefer using PutRecords for most applications because it will achieve higher throughput per data producer.
Using Kinesis Agent – Kinesis Agent is a stand-alone Java software application that offers an easy way to collect and send data to Kinesis Data Streams. The agent continuously monitors a set of files and sends new data to your stream. The agent handles file rotation, checkpointing, and retry upon failures. It delivers all of your data in a reliable, timely, and simple manner. It also emits Amazon CloudWatch metrics to help you better monitor and troubleshoot the streaming process. By default, records are parsed from each file based on the newline (‘\n’) character. Your operating system must be either Amazon Linux AMI with version 2015.09 or later, or Red Hat Enterprise Linux version 7 or later.
Using Consumers with Enhanced Fan-Out – In Amazon Kinesis Data Streams, you can build consumers that use a feature called enhanced fan-out. This feature enables consumers to receive records from a stream with throughput of up to 2 MiB of data per second per shard. This throughput is dedicated, which means that consumers that use enhanced fan-out don’t have to contend with other consumers that are receiving data from the stream. Kinesis Data Streams pushes data records from the stream to consumers that use enhanced fan-out. Therefore, these consumers don’t need to poll for data. You can register up to five consumers per stream to use enhanced fan-out. If you need to register more than five consumers, you can request a limit increase
Splitting a Shard – To split a shard in Amazon Kinesis Data Streams, you need to specify how hash key values from the parent shard should be redistributed to the child shards. When you add a data record to a stream, it is assigned to a shard based on a hash key value. The hash key value is the MD5 hash of the partition key that you specify for the data record at the time that you add the data record to the stream. Data records that have the same partition key also have the same hash key value.
Merging Two Shards – A shard merge operation takes two specified shards and combines them into a single shard. After the merge, the single child shard receives data for all hash key values covered by the two parent shards. To merge two shards, the shards must be adjacent. Two shards are considered adjacent if the union of the hash key ranges for the two shards forms a contiguous set with no gaps. For example, suppose that you have two shards, one with a hash key range of 276…381 and the other with a hash key range of 382…454. You could merge these two shards into a single shard that would have a hash key range of 276…454.
Kinesis Data Streams Consumers
A consumer, known as an Amazon Kinesis Data Streams application, is an application that you build to read and process data records from Kinesis data streams. If you want to send stream records directly to services such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), or Splunk, you can use a Kinesis Data Firehose delivery stream instead of creating a consumer application.
AWS Kinesis Data Firehose
Amazon Kinesis Data Firehose is a fully managed service for delivering real-time streaming data to destinations such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), and Splunk. Kinesis Data Firehose is part of the Kinesis streaming data platform, along with Kinesis Data Streams, Kinesis Video Streams, and Amazon Kinesis Data Analytics. With Kinesis Data Firehose, you don’t need to write applications or manage resources. You configure your data producers to send data to Kinesis Data Firehose, and it automatically delivers the data to the destination that you specified.
Terminology
- record – The data of interest that your data producer sends to a Kinesis Data Firehose delivery stream. A record can be as large as 1,000 KB.
- data producer – Producers send records to Kinesis Data Firehose delivery streams. For example, a web server that sends log data to a delivery stream is a data producer. You can also configure your Kinesis Data Firehose delivery stream to automatically read data from an existing Kinesis data stream, and load it into destinations.
- buffer size and buffer interval – Kinesis Data Firehose buffers incoming streaming data to a certain size or for a certain period of time before delivering it to destinations. Buffer Size is in MBs and Buffer Interval is in seconds.
Data Flow
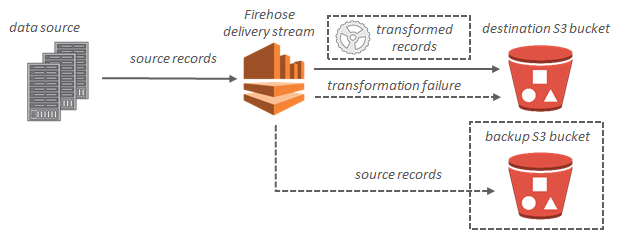
For Amazon S3 destinations, streaming data is delivered to your S3 bucket. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket.
Amazon Kinesis Data Firehose data flow for Amazon S3
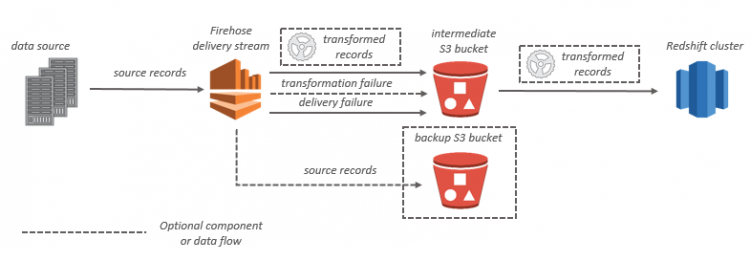
For Amazon Redshift destinations, streaming data is delivered to your S3 bucket first. Kinesis Data Firehose then issues an Amazon Redshift COPY command to load data from your S3 bucket to your Amazon Redshift cluster. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket.
Amazon Kinesis Data Firehose data flow for Amazon Redshift
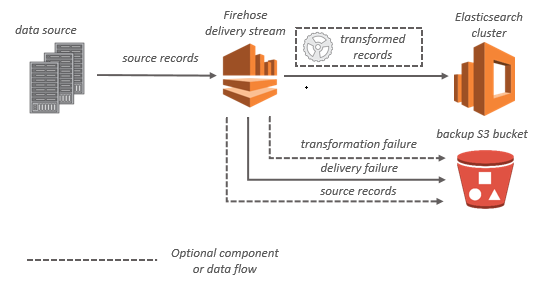
For Amazon ES destinations, streaming data is delivered to your Amazon ES cluster, and it can optionally be backed up to your S3 bucket concurrently.
Amazon Kinesis Data Firehose data flow for Amazon ES
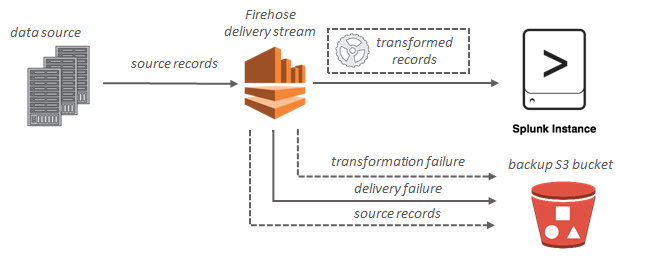
For Splunk destinations, streaming data is delivered to Splunk, and it can optionally be backed up to your S3 bucket concurrently.
Amazon Kinesis Data Firehose data flow for Splunk
Link for free practice test – https://www.testpreptraining.com/aws-certified-big-data-specialty-free-practice-test