AWS Certified Solutions Architect Associate Interview Questions

The AWS Certified Solutions Architect Associate certification is one of the most sought-after certifications in the cloud computing industry. It validates the skills and expertise required to design and deploy scalable, highly available, and fault-tolerant systems on the Amazon Web Services (AWS) platform. In this blog post, we will cover some of the most commonly asked AWS Certified Solutions Architect Associate interview questions. These questions will cover a wide range of topics, including AWS services, architecture patterns, security, and cost optimization.
Whether you are preparing for an interview for a Solutions Architect role or just looking to brush up on your AWS knowledge, this blog post will provide you with valuable insights and help you ace your interview. So, let’s dive in and explore some of the most important AWS Certified Solutions Architect Associate (SAA-C02) interview questions.
To help you in your interview preparation, we have curated a number of questions.

What are the main components of Amazon Web Services (AWS) and how do they work together?
Amazon Web Services (AWS) is a collection of remote computing services (also called web services) that make up a cloud computing platform, offered by Amazon.com. The main components of AWS include:
- Compute: This category includes services that allow you to run and manage virtual machines (VMs), containers, and serverless functions. The most popular services in this category are Amazon Elastic Compute Cloud (EC2) and AWS Lambda.
- Storage: This category includes services that allow you to store and manage data in the cloud. The most popular services in this category are Amazon Simple Storage Service (S3) and Amazon Elastic Block Store (EBS).
- Database: This category includes services that allow you to store and manage structured data in the cloud. The most popular services in this category are Amazon Relational Database Service (RDS) and Amazon DynamoDB.
- Networking: This category includes services that allow you to create and manage virtual networks in the cloud. The most popular services in this category are Amazon Virtual Private Cloud (VPC) and Amazon Route 53.
- Analytics: This category includes services that allow you to process and analyze large amounts of data. The most popular services in this category are Amazon Elastic MapReduce (EMR) and Amazon Redshift.
- Security and Identity: This category includes services that allow you to secure and control access to your AWS resources. The most popular services in this category are Amazon Identity and Access Management (IAM) and Amazon GuardDuty.
These components work together to provide a complete and flexible platform for building, deploying, and scaling applications and services in the cloud. Each service is designed to be highly available, scalable, and fault-tolerant, and can be used in combination with other services to build complex and powerful solutions.
What is Amazon Elastic Container Service (ECS) and how does it work?
Amazon Elastic Container Service (ECS) is a fully-managed container orchestration service that allows you to easily run, scale, and manage Docker containers on the Amazon Web Services (AWS) cloud. ECS provides a simple API and user interface to manage and deploy Docker containers to a cluster of EC2 instances or Fargate instances.
ECS provides the following benefits:
- Easy deployment: You can quickly deploy and manage containers using the ECS console, CLI, or API.
- Scalability: ECS automatically scales your container instances based on demand.
- High availability: ECS automatically distributes your containers across multiple Availability Zones to provide high availability.
- Security: ECS integrates with AWS Identity and Access Management (IAM) to provide secure access to your container instances.
- Monitoring: ECS provides metrics and logs to monitor your containers and applications.
ECS works by creating a cluster of EC2 instances or Fargate instances, where each instance runs the ECS agent. The ECS agent is a small daemon that runs on each instance in the cluster and communicates with the ECS service to manage containers.
To use ECS, you first need to create a cluster, which is a logical grouping of container instances. You can create a cluster using the ECS console, CLI, or API. Once you have a cluster, you can create a task definition that describes the Docker containers you want to run, along with their configuration and dependencies. You can then launch tasks from the task definition onto the cluster, which creates containers on the container instances.
ECS provides different scheduling options, such as placement constraints and task placement strategies, to ensure that your containers are placed on the optimal container instances. ECS also provides load balancing options using Elastic Load Balancing (ELB) to distribute traffic across your containers.
How can you automate infrastructure deployments using AWS CodePipeline and AWS CodeBuild?
AWS CodePipeline and AWS CodeBuild are two powerful services that can be used together to automate infrastructure deployments in AWS.
AWS CodePipeline is a fully managed continuous delivery service that helps you automate the release process for your applications. CodePipeline can be used to orchestrate the entire release process, from building and testing your application code to deploying it to your production environment.
AWS CodeBuild is a fully managed build service that compiles your source code, runs tests, and produces packages that are ready for deployment. CodeBuild can be used to build applications and infrastructure, including Docker containers, AWS CloudFormation templates, and serverless applications.
Here’s how you can automate infrastructure deployments using AWS CodePipeline and AWS CodeBuild:
- Define your pipeline: First, define the stages in your pipeline, which typically include source, build, test, and deploy. You can use the CodePipeline console, CLI, or API to define your pipeline.
- Connect to your source repository: Next, connect CodePipeline to your source code repository, such as GitHub, AWS CodeCommit, or Amazon S3.
- Use CodeBuild for building and testing: In the build stage of your pipeline, use CodeBuild to compile your source code, run tests, and package your application or infrastructure. You can use CodeBuild to build any type of code, including Docker containers, AWS CloudFormation templates, and serverless applications.
- Deploy with AWS CloudFormation or AWS Elastic Beanstalk: In the deploy stage of your pipeline, use AWS CloudFormation or AWS Elastic Beanstalk to deploy your application or infrastructure to your AWS environment. AWS CloudFormation can be used to deploy and manage AWS resources, while Elastic Beanstalk provides a platform for deploying and managing web applications.
- Monitor your pipeline: Finally, use the CodePipeline console to monitor your pipeline and view the status of your builds and deployments.
By automating your infrastructure deployments using AWS CodePipeline and AWS CodeBuild, you can improve the speed and reliability of your deployments while reducing the risk of errors and downtime.
How can you use AWS Lambda with other AWS services like Amazon S3 and Amazon DynamoDB?
AWS Lambda can be integrated with a wide range of AWS services, including Amazon S3 and Amazon DynamoDB, to build highly scalable and efficient serverless applications. Here are some ways you can use AWS Lambda with these services:
- Using Lambda with Amazon S3: You can use AWS Lambda to automatically process objects that are uploaded to an Amazon S3 bucket. For example, you can create a Lambda function that is triggered by an S3 event, such as object creation or deletion, to process the object and perform actions such as resizing images, extracting metadata, or validating the data. You can also use Lambda to automatically replicate objects across different S3 buckets or regions.
- Using Lambda with Amazon DynamoDB: You can use AWS Lambda to process data that is stored in Amazon DynamoDB. For example, you can create a Lambda function that is triggered by a DynamoDB stream event, such as a new record insertion, to perform real-time processing, such as aggregating data, sending notifications, or updating other systems. You can also use Lambda to build serverless APIs that interact with DynamoDB, such as querying or updating data based on API requests.
- Using Lambda with Amazon API Gateway: You can use AWS Lambda with Amazon API Gateway to build scalable and secure serverless APIs that can integrate with a wide range of services, including S3 and DynamoDB. API Gateway provides a simple way to create RESTful APIs that can trigger Lambda functions based on HTTP requests. You can use Lambda to process the request data, authenticate the user, and interact with other services to provide a response.
- Using Lambda with AWS Step Functions: You can use AWS Lambda with AWS Step Functions to build complex serverless workflows that orchestrate multiple services, including S3 and DynamoDB. Step Functions provide a visual interface to define state machines that execute a series of steps, including Lambda functions, based on input data and conditions. You can use Lambda to perform specific tasks within the workflow, such as data processing or interaction with external services.
How would you design a highly available and scalable architecture on AWS?
Designing a highly available and scalable architecture on AWS typically involves several key steps, including:
- Identifying the critical components of your application: Determine which parts of your application are most critical to its availability and scalability, and focus on designing those components to be highly available and scalable.
- Using multiple availability zones: Distribute your resources across multiple availability zones (AZs) within a region to protect against failures in a single AZ.
- Using Amazon Elastic Load Balancer (ELB) or Application Load Balancer (ALB): Use an ELB or ALB to distribute incoming traffic across multiple instances of your application, providing automatic failover and scaling.
- Using Auto Scaling: Use Auto Scaling to automatically adjust the number of instances running your application based on changes in traffic and resource utilization.
- Using Amazon RDS Multi-AZ or Amazon Aurora Replicas: Use Amazon RDS Multi-AZ or Amazon Aurora Replicas to provide automatic failover and replication for your database.
- Using Amazon S3 and Amazon EBS: Use Amazon S3 for object storage and Amazon EBS for block storage, both services provide high durability and availability.
- Using Amazon CloudFront: Use Amazon CloudFront for Content Delivery Network (CDN) and caching, it will help to reduce the load on your origin servers.
It’s important to keep in mind that there is no one-size-fits-all solution and the best architecture will depend on the specific requirements of your application. It’s also important to keep in mind security and compliance aspect while designing this architecture.
Can you explain the difference between Amazon Elastic Compute Cloud (EC2) and Amazon Elastic Block Store (EBS)?
Amazon Elastic Compute Cloud (EC2) and Amazon Elastic Block Store (EBS) are both services provided by AWS, but they serve different purposes.
EC2 is a web service that provides resizable compute capacity in the cloud. It allows you to launch and manage virtual machines (also known as instances) in the cloud. You can choose from a variety of instance types and configurations, and pay for the resources you use on a per-hour or per-second basis.
EBS, on the other hand, is a block storage service for EC2 instances. It provides persistent storage for data that you want to keep separate from the instance itself. EBS volumes are network-attached storage (NAS) and can be used as the primary storage for an instance, or as a place to store data that you want to persist after the instance is terminated.
In summary, EC2 provides the computing power and resources needed to run an application or service, while EBS provides persistent storage for data that you want to keep separate from the instance. Together, EC2 and EBS can be used to build a complete, highly available, and scalable infrastructure in the AWS cloud.
How would you go about securing an AWS infrastructure?
Securing an AWS infrastructure involves implementing a combination of security controls and best practices to protect your data, applications, and resources. Here are a few steps you can take to secure your AWS infrastructure:
- Use AWS Identity and Access Management (IAM) to control access to your AWS resources: Use IAM to create users, groups, and roles, and then assign permissions to those entities. This allows you to grant or deny access to specific resources based on the principle of least privilege.
- Use Virtual Private Clouds (VPCs) to segment your network: Use VPCs to create isolated virtual networks within the AWS environment. This allows you to control access to your resources and isolate them from the public internet.
- Use security groups and Network Access Control Lists (NACLs) to control network traffic: Security groups and NACLs allow you to control inbound and outbound traffic to your resources. Use them to restrict access to only the necessary ports and protocols.
- Use encryption to protect data: Use AWS Key Management Service (KMS) to encrypt your data at rest and in transit. Use Amazon S3 bucket policies and Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) to encrypt your S3 data.
- Use Amazon CloudWatch to monitor your environment: Use CloudWatch to monitor your resources, applications, and services. Set up alarms to be notified when certain thresholds are breached.
- Use AWS Config to track changes to your environment: Use AWS Config to track changes to your resources, so you can quickly identify and respond to any unauthorized changes.
By implementing these steps and regularly reviewing and updating your security policies, you can effectively secure your AWS infrastructure and protect your data, applications, and resources from potential threats.
How would you troubleshoot and resolve an issue with an Amazon Elastic Block Store (EBS) volume?
Here are a few steps you can take to troubleshoot and resolve an issue with an Amazon Elastic Block Store (EBS) volume:
- Identify the problem: The first step is to identify the problem. This can be done by checking the CloudWatch metrics and logs for the affected EBS volume. You can also check the status of the volume in the AWS Management Console.
- Check the attachment: Make sure that the EBS volume is attached to the correct instance and that it is in the correct availability zone.
- Check the in-use status: Make sure that the volume is not in use by another process or application.
- Check the file system: Make sure that the file system on the volume is in a healthy state. Run the appropriate file system check command (e.g. fsck) on the volume.
- Take a snapshot: If the volume is not recoverable, take a snapshot of the volume and create a new volume from the snapshot.
- Check the permissions: Check that the IAM role associated with the instance has appropriate permissions to access the volume.
- Check the network: Check that the security group associated with the instance and the volume are configured to allow traffic on the correct ports.
Overall, troubleshooting an issue with an EBS volume requires a systematic approach. By identifying the problem, checking the attachment and in-use status, checking the file system, taking a snapshot, checking the permissions, network and the driver, you can quickly and effectively troubleshoot and resolve the issue. If the issue still persists, contacting the AWS Support team will be the next step.
How would you use Amazon CloudWatch to monitor your AWS resources?
Amazon CloudWatch is a service that allows you to monitor your AWS resources and the applications you run on AWS. Here are a few ways you can use Amazon CloudWatch to monitor your AWS resources:
- Monitoring Metrics: CloudWatch allows you to collect and track metrics for your resources, such as CPU usage and network traffic for your Amazon EC2 instances, and error rates for your Amazon S3 buckets. You can also create custom metrics to track specific business-related data.
- Alarms: CloudWatch allows you to set alarms on your metrics. For example, you can set an alarm to notify you if the CPU usage of one of your EC2 instances exceeds 90% for a certain period of time.
- Logs: CloudWatch allows you to collect and monitor logs from your resources. You can use CloudWatch Logs Insights to search and analyze your logs, which can help you troubleshoot issues with your resources.
- Dashboards: CloudWatch allows you to create custom dashboards that show the status of your resources at a glance. You can add widgets to your dashboards that display metrics, alarms, and logs.
Overall, Amazon CloudWatch is a powerful service that allows you to monitor your AWS resources and the applications you run on AWS. It provides a wide range of monitoring capabilities, such as metrics, alarms, logs, dashboards and events, that you can use to keep an eye on your resources and ensure that they are running optimally.
Can you explain the use of Amazon Elastic Load Balancer (ELB) and Auto Scaling in a web application?
Amazon Elastic Load Balancer (ELB) and Auto Scaling are two services that can be used together to create a highly available and scalable web application on AWS.
Amazon Elastic Load Balancer (ELB) is a service that automatically distributes incoming web traffic across multiple Amazon Elastic Compute Cloud (EC2) instances. ELB can automatically scale to handle increased traffic and can also route traffic to healthy instances while routing traffic away from unhealthy instances.
Auto Scaling is a service that automatically scales an application up or down based on predefined rules or policies. Auto Scaling can be used to automatically add or remove EC2 instances as the traffic to your application changes.
When ELB and Auto Scaling are used together, they can automatically handle changes in traffic and ensure that your application is always available and responsive. This can be done by creating an ELB in front of the Auto Scaling group, ELB will automatically route the traffic to the healthy instances in the group. When the traffic increases, Auto Scaling will automatically spin up new instances to handle the increased traffic and when the traffic decreases, it will terminate the instances that are no longer needed.
For example, imagine that you have an e-commerce website that experiences a spike in traffic during the holiday season. Using ELB and Auto Scaling, you could configure your application to automatically scale up to handle the increased traffic during the holiday season and then scale down when traffic returns to normal levels.
How would you implement disaster recovery for an application running on AWS?
Here’s an overview of how to implement disaster recovery for an application running on AWS:
- Identify critical resources: The first step in implementing disaster recovery is to identify the critical resources that your application relies on. This could include databases, servers, storage, and networking components.
- Create a disaster recovery plan: Once you’ve identified your critical resources, you can create a disaster recovery plan that outlines the steps you’ll take to recover your application in the event of a disaster. The plan should include procedures for testing, failover, and failback.
- Use Amazon Route 53 for failover: Amazon Route 53 is a scalable Domain Name System (DNS) service that can be used to route traffic to different resources based on the health of those resources. You can use Route 53 to configure a failover mechanism that redirects traffic to a secondary resource in the event that the primary resource becomes unavailable.
- Use Amazon S3 for data backup and recovery: Amazon S3 is a highly durable and scalable object storage service that can be used to store and retrieve data in the event of a disaster. You can use S3 to store backups of your application data and to retrieve that data in the event of a disaster.
- Use Amazon RDS for database replication: Amazon Relational Database Service (RDS) is a fully managed relational database service that can be used to create a replica of your database in a different region. This can be used to ensure that your application can continue to access the data it needs even if the primary database becomes unavailable.
By following these steps, you can implement a disaster recovery plan for your application running on AWS that will help ensure that your application remains available and accessible even in the event of a disaster.
How would you set up a VPC and configure security groups and network ACLs?
Here’s an overview of how to set up a Virtual Private Cloud (VPC) and configure security groups and network access control lists (ACLs) on AWS:
- Set up a VPC: To create a VPC, you can use the VPC wizard in the AWS Management Console. The wizard will guide you through the process of creating a VPC, including selecting a CIDR block, creating subnets, and configuring route tables.
- Create security groups: After setting up the VPC, you can create security groups. Security groups act as a virtual firewall for your instances and allow you to control incoming and outgoing traffic. You can create security groups for different types of instances and configure rules for each group.
- Configure network ACLs: Network ACLs provide an additional layer of security for your VPC. You can create rules to allow or deny traffic based on the IP protocol, source and destination IP address, and port number. It is best practice to create a separate network ACL for each subnet in your VPC.
- Add instances to security groups and network ACLs: After creating security groups and network ACLs, you can associate them with your instances. This will ensure that only the traffic specified in the security group and network ACL rules is allowed to access your instances.
By following these steps, you can set up a secure and reliable VPC on AWS, and configure security groups and network ACLs to control traffic to and from your instances.
How would you configure Amazon Simple Storage Service (S3) for high availability and durability?
Here are a few ways to configure Amazon Simple Storage Service (S3) for high availability and durability:
- Use multiple availability zones: By storing data in multiple availability zones, you can ensure that your data is available even if one availability zone becomes unavailable. This can be achieved by using Amazon S3’s cross-region replication feature.
- Use versioning: By enabling versioning on your S3 bucket, you can ensure that all versions of an object are stored, including deleted versions. This can help you recover from accidental deletions or overwrites.
- Use Lifecycle policies: You can use Amazon S3 Lifecycle policies to automatically transition objects to different storage classes, such as Amazon S3 Standard-Infrequent Access or Amazon Glacier, based on the age of the object. This can help you save costs while still maintaining high availability and durability.
- Use Amazon S3 Select and Amazon S3 Glacier Select: By using these services, you can perform complex data filtering and analysis on your data stored in Amazon S3 and Amazon S3 Glacier without having to retrieve the entire object.
- Use Amazon S3 Inventory: By using this service, you can generate reports of your S3 bucket inventory, including the object’s metadata and encryption status. This can help you identify any issues with your data and take action to resolve them.
- Use Amazon S3 Event Notifications: You can use this service to be notified of certain events, such as when an object is created or deleted, and take appropriate action.
By implementing these strategies, you can ensure that your data stored in Amazon S3 is highly available and durable, and that you can recover from any potential issues.

What do you mean by AWS?
It’s one of the most common AWS interview questions. There isn’t much space for creativity because you either know or don’t know the answer.
Amazon Web Services, or AWS, is a set of Amazon’s cloud computing services and resources. It provides more than 200 integrated data centre facilities around the world. AWS is a multi-functional network that provides a wide range of services, from data warehousing to cloud computing.
What exactly is Amazon S3?
Amazon S3 (Easy Storage Service) is an object storage service with a simple web service interface that allows you to store and retrieve any amount of data from anywhere on the internet.
What is AWS SNS, and how does it work?
Amazon Simple Notification Service (Amazon SNS) is a push notification service that allows you to send individual messages to a large number of smartphone or email subscribers using Amazon SQS queues, AWS Lambda functions, and HTTPS endpoints. Application-to-application (A2A) and application-to-person (A2P) communication are also supported.
What exactly is sharding?
Sharding, also known as horizontal partitioning, is a relational database scale-out technique. This method divides the data into smaller chunks and distributes them through physically separate database servers, each of which is referred to as a database shard. Since these database shards share the same hardware, database engine, and data structure, they function similarly.
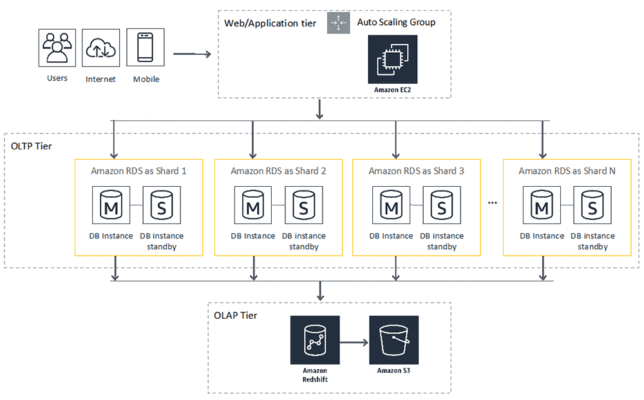
Source: AWS Blog
What are the various forms of load balancers available in EC2?
In EC2, there are three types of load balancers:
- Application Load Balancer – These load balancers are used to make application-level routing decisions.
- Network Load Balancer: A network load balancer manages millions of requests per second and assists in transport layer routing decisions.
- Classic Load Balancer: Classic Load Balancer is mostly used for EC2-Classic network applications. It provides simple load balancing across a number of Amazon EC2 instances.
What exactly is DynamoDB?
DynamoDB is a NoSQL (non-relational) database. It’s extremely adaptable and dependable, and it’s compatible with AWS! It provides smooth scalability as well as fast and predictable results. You won’t have to think about hardware provisioning, setup, and configuration, replication, software patching, or cluster scaling with DynamoDB.
What is AWS CloudFormation, and how does it work?
AWS CloudFormation is an Amazon service committed to addressing the need to standardise and replicate architectures in order to simplify their implementation and reduce resources and costs in the delivery of software, or compliance with organisational requirements. Via programming, CloudFormation enables the development of a proprietary library of instance templates or architectures that can be provided at any time and in a well-organized manner.
What are the benefits of using Amazon Web Services CloudFormation?
One of the most popular AWS interview questions is this one.
- AWS CloudFormation is a service provided by Amazon Web Services.
- Reduces the time it takes to deploy technology
- Reduces the time it takes to restore the environment
- Increases deployment trust
- Replicates complex environments, for example, by scaling up resources to create complex environments for construction, pre-production, and production that are the same or nearly the same.
- Refreshes the distinctions between various goods.
What is Elastic Beanstalk, and how does it work?
Elastic Beanstalk is an AWS orchestration service that is used in EC2, S3, Simple Notification Service, CloudWatch, autoscaling, and Elastic Load Balancers, among other AWS applications. Using the AWS Management Console, a Git repository, or an optimised development environment, it is the quickest and easiest way to deploy your application on AWS (IDE).
What is CloudFront’s Geo Restriction?
Geo restriction, also known as geoblocking, is used to prohibit users from accessing content distributed via a CloudFront network distribution from unique geographic locations.
What does a T2 instance entail?
T2 instances are intended to provide a moderate baseline performance with the potential to burst to higher performance when workload demands it.
What is AWS Lambda and how does it work?
AWS Lambda is a compute utility that allows you to run code without having to provision or manage servers in the AWS Cloud.
In AWS, what is a serverless application?
AWS Serverless Application Model (AWS SAM) is an extension of AWS CloudFormation that makes it easier to define the Amazon API Gateway APIs, AWS Lambda functions, and Amazon DynamoDB tables that your serverless application needs.
What is Amazon ElastiCache’s purpose?
Amazon ElastiCache is a cloud-based web service that makes it simple to set up, manage, and scale an in-memory data store or cache.
Explain how Amazon’s web services use the buffer.
By synchronising various elements, the buffer makes the device more stable in terms of managing traffic or load.
Distinguish between stopping and terminating a process.
When an instance is stopped, it goes through a standard shutdown before entering the stopped state. When an instance is terminated, it shuts down normally, and the attached Amazon EBS volumes are removed unless the deleteOnTermination attribute on the volume is set to false.
Is it possible to modify an EC2’s private IP addresses when it is running or stopped in a VPC?
It is not possible to change the primary private IP address. At any time, you can unassign, delegate, or transfer secondary private addresses between interfaces or instances.
Can you provide an example of when you’d prefer Provisioned IOPS storage over Standard RDS storage?
When we have batch-oriented workloads, Provisioned IOPS can be favoured over Standard RDS storage.
What are the various cloud service types?
The following are examples of cloud services:
- Firstly, As a Service (SaaS) (SaaS)
- Information as a Service (DaaS)
- Software as a Service (SaaS) (PaaS)
- Infrastructure as a Service (IaaS) is a type of cloud (IaaS)
How long does it take for an instance store-backed instance to boot?
An Amazon Instance Store-Backed AMI takes less than 5 minutes to boot.
Would you encrypt your S3 data?
Since it is a proprietary technology, I will. When storing confidential data on S3, it’s always a good idea to think about encryption.
What exactly is Identity Access Management, and how does it work?
It is a web service that is used to manage access to AWS resources in a safe manner. You can handle users, security credentials, and resource permissions with Identity Access Management.
Describe the benefits of AWS’ Disaster Recovery (DR) service.
The following are some of the benefits of AWS’ Disaster Recovery (DR) service:
- Firstly, AWS provides a cost-effective backup, storage, and disaster recovery solution, allowing businesses to save money on capital expenditures.
- Secondly, Increased efficiency and reduced setup time
- Thirdly, AWS enables businesses to scale up even in the face of seasonal volatility.
- Next, It replicates data from on-premises to the cloud in real time.
- Last but not least, Ensures that files can be retrieve quickly.
What is the best way to send requests to Amazon S3?
Using the REST API or the AWS SDK wrapper modules, we can accomplish this. These components encapsulate the Amazon S3 REST API.
What exactly is DynamoDB?
DynamoDB is a proprietary NoSQL database service that supports key-value and document data structures and is completely manage. When a fast and scalable NoSQL database with a flexible data model and consistent performance is needed, this is the database to use.
What exactly is Redshift?
Redshift is Amazon’s petabyte-scale data warehouse program. It’s easy, affordable, and scalable, and it can be completely customize to analyze all of your data using existing business intelligence tools.
What types of data centres are use for cloud computing?
In cloud computing, there are two types of data centres: containerized data centres and low-density data centres.
Which AWS services can you use to collect and process e-commerce data in order to analyse it in near real time?
The following AWS services will be use to collect and process e-commerce data for analysis in near real-time:
- ElastiCache from Amazon
- Elastic MapReduce on Amazon
- Redshift is a service provided by Amazon.
What exactly is SQS?
Simple Queue Service (SQS) is a distributed message queuing service that serves as a middleman between two controllers. It’s a web service that you have to pay for each time you use it.
What are the most widely used DevOps tools?
The most widely used DevOps methods are –
- Firstly, Deployment and Configuration Management Tools: Chef, Puppet, Ansible, and SaltStack
- Secondly, Docker is containerization software.
- Thirdly, Git is a tool for version control
- Next, Jenkins is a tool for continuous integration.
- Further, Nagios is a tool for continuous monitoring.
- Last but not least, Selenium is a tool for continuous testing.
What does it mean to have a hybrid cloud architecture?
It’s a form of architecture in which the workload is split into two halves, one of which is dedicate to public load and the other to local storage. Between two channels, it combines on-premises, private cloud and third-party, and public cloud services.
What Is Configuration Management and How Does It Work?
Configuration management is a software-based approach to managing the configuration of devices and the services they offer. This is a repeatable and reliable procedure that is accomplishe by –
- Command-line gui that is easy to use
- A domain-specific language that is lightweight and easy to learn (DSL)
- REST-based API with a lot of features
Mention any communication problems you’ve had when connecting to an EC2 instance?
When connecting to an EC2 case, you can encounter the following connection issues:
- Firstly, The server declined to accept the key.
- Secondly, The link was lost.
- Thirdly, Permission refused due to host key not being identified.
- Next, External key file that isn’t password-protected
- Last but not least, There is no authentication method that is supported.
What are AWS autoscaling lifecycle hooks?
The autoscaling community may have lifecycle hooks attached to it. It allows you to perform custom acts by pausing and resuming instances where the autoscaling community terminates. There are several lifecycle hooks in each auto-scaling category.
What is a Hypervisor, and how does it work?
A hypervisor is a piece of software that allows you to build and manage virtual machines. It combines physical hardware resources into a platform that is virtualize and distribute to each user. Oracle Virtual Box, Oracle VM for x86, VMware Fusion, VMware Workstation, and Solaris Zones are examples of hypervisors.
Describe how to use a Route Table.
Each subnetwork of the VPC is associate with a routing table, which is use to manage network traffic. A routing table contains a lot of data, and it’s even possible to link several subnetworks to it.
What is Connection Draining’s purpose?
Connection draining is a load balancer support mechanism. It keeps track of all the instances and, if one fails, it drains all traffic from that failed instance and reroutes it to the successful ones.
What is the role of AWS CloudTrail?
AWS CloudTrail is a service that allows you to monitor and audit API call behaviour. With AWS CloudTrail, the user can keep track of account behaviour associated with AWS infrastructure activities.
What is Amazon Transfer Acceleration Service and how does it work?
The Amazon Upload Acceleration Service uses advanced network paths to speed up the data transfer. It also secures and speeds up file transfers between your client and an S3 bucket.
What is Amazon Route 53 and how does it work?
A scalable and highly accessible Domain Name System is known as Amazon Route 53. (DNS). It is design to help developers and businesses route end users to web applications by translating names, which is the most efficient and cost-effective method.
What are the positions of the edges?
The position where the content is cache is refer to as an edge spot. If a user needs to access any information, the information will be search in the edge area. If it isn’t available, the material will be available from the original site, and a copy will be held.
