Neural Networks Google Professional Data Engineer GCP
In this, we will learn about the concepts of Neural Networks.
What are Neural Networks?
- It has multiple nodes that interconnects to each other,
- mimics the neurons in our brain.
- Each neuron inputs from another neuron, performs tasks, and transfers to another as output.
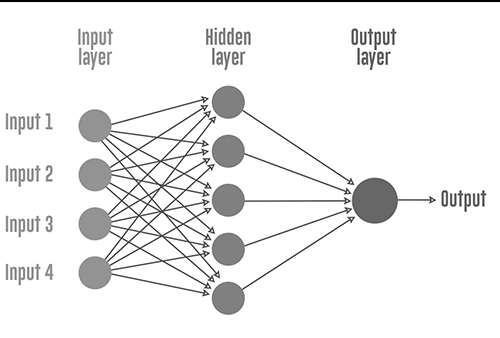 In figure
In figure
- Each circular node is an artificial neuron
- arrow represents a connection from the output of one neuron to the input of another.
Layers
- As per diagram, there are 4 layers present – Layer 1, Layer 2, Layer 3 and Layer 4.
- Every deep neural network consists of three types of layers, which are:
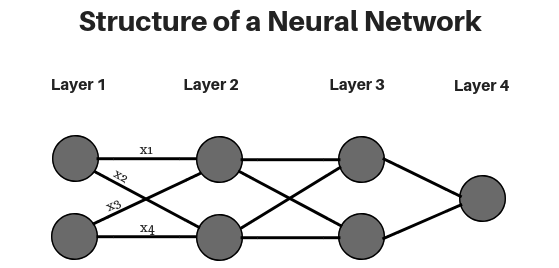
- Input Layer (Layer 1): provides the input parameters and passes parameters to further layers without any computation at this layer.
- Hidden Layers (Layers 2 and 3): Perform the computations on the inputs receiving from the previous layers and pass on the result to the next layer. More the number of hidden layers, deeper is the network.
- Output Layer (Layer 4): gives final output after receiving the results from the previous layers.
Weights
- This attaches some weightage to a certain feature.
- Some features might be more important than others
- weights calculate the weighted sum for each neuron. x1, x2, x3, x4 represent the weights associated with the corresponding connections in the deep neural network.
Activation Function
- decide if a neuron to activate or not depending on their weight sum.
- hidden layer has an activation function associated with it.
Backpropagation
- This is for neural net training.
- For fine-tuning weights of a neural net based on the error rate obtained in the previous epoch (i.e., iteration).
- Proper tuning of weights reduce error rates and make model reliable.
- Backpropagation is a short form for “backward propagation of errors.”
- standard method of training artificial neural networks.
- calculate the gradient of a loss function with respects to all the weights in the network.
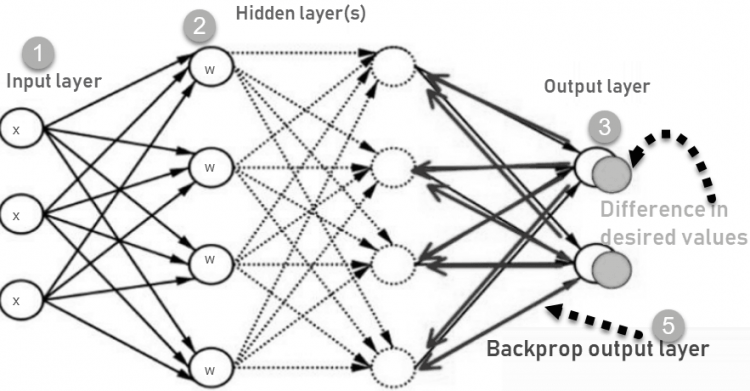 Backpropagation
Backpropagation
- Inputs X, arrive through the preconnected path
- Input is modeled using real weights W, randomly selected.
- Calculate the output for every neuron from the input layer, to the hidden layers, to the output layer.
- Calculate the error in the outputs: ErrorB= Actual Output – Desired Output
- Travel back from the output layer to the hidden layer to adjust the weights such that the error is decreased.
- Keep repeating the process until the desired output is achieved
Backpropagation Networks Types:
- Static back-propagation: produces mapping of a static input for static output.
- Recurrent Backpropagation: It is fed forward until a fixed value is achieved. After that, the error is computed and propagated backward.
Feature requirements for feature engineering
- should be reasonably related
- Feature value should be known at the time of prediction without latency
- Numeric with range of meaningful magnitude.
- Difficult for categorical inputs.
- Need to find vector/bitmask representation(1 hot encoding), for NL, we can use wordtovec.
- Need to have enough examples of each feature value.
- For continuous numbers, use windows.
- Feature crosses can be done using human sights, this will simplify ml model.
Model architecture
- Linear models work well for sparse features(like employee id).
- Neural network model works well for dense features(like price, color(rgb))
- Regressor – linear, sparse features, specific, many features, memorization, employee id, nlp
- DNN – non-linear, dense features, generalization, color, price
- Wide and linear – combination of both, recommendation, search and ranking
Hypertuning
- Changing model parameters to find the right set of parameters for a particular result.
- evaluate rmse with the parameter and keep tuning to lower rmse.
- define what metric we want for evaluation like rmse.
Reinforcement Machine Learning Algorithms
- A type of Machine Learning where machine is required to determine the ideal behaviour within a specific context, in order to maximize its rewards.
- It works on the rewards and punishment principle
- for any decision which a machine takes, it will be either be rewarded for correct or punished.
- So machine will learn to take the correct decisions to maximize the reward in the long run.
- Can focus on long-term rewards or the short-term rewards.
- If machine is in a specific state and has to be the action for the next state in order to achieve the reward, it is called the Markov Decision Process.
- The environment is modelled as a stochastic finite state machine with
- inputs (actions sent from the agent)
- outputs (observations and rewards sent to the agent)
- It requires clever exploration mechanisms.
- Selection of actions with careful reference to the probability of an event
- It is memory expensive to store the values of each state
Important terms
- Agent: It is an assumed entity which performs actions in an environment to gain some reward.
- Environment (e): A scenario that an agent has to face.
- Reward (R): An immediate return given to an agent when he or she performs specific action or task.
- State (s): State refers to the current situation returned by the environment.
- Policy (π): It is a strategy which applies by the agent to decide the next action based on the current state.
- Value (V): It is expected long-term return with discount, as compared to the short-term reward.
- Value Function: It specifies the value of a state that is the total amount of reward. It is an agent which should be expected beginning from that state.
- Model of the environment: This mimics the behavior of the environment. It helps you to make inferences to be made and also determine how the environment will behave.
- Model based methods: It is a method for solving reinforcement learning problems which use model-based methods.
- Q value or action value (Q): Q value is quite similar to value. The only difference between the two is that it takes an additional parameter as a current action.
Example:
Example of cat training
- cat is an agent that is exposed to the environment. In this case, it is house. An example of a state could be cat sitting, and you use a specific word in for cat to walk.
- Our agent reacts by performing an action transition from one “state” to another “state.”
- For example, cat goes from sitting to walking.
- The reaction of an agent is an action, and the policy is a method of selecting an action given a state in expectation of better outcomes.
- After the transition, they may get a reward or penalty in return.
Approaches to implement a Reinforcement Learning algorithm.
- Value-Based: try to maximize a value function V(s).
- Policy-based: try to come up with such a policy that the action performed in every state helps you to gain maximum reward in the future.
- Model-Based: need to create a virtual model for each environment.