Configure input and output
In this we will learn about configuring input and output using the steam data and Azure stem analytics.
Stream data as input into Stream Analytics
Stream Analytics has first-class integration with Azure data streams as inputs from three kinds of resources. They are Azure Event Hubs, Azure IoT Hub, Azure Blob storage and Azure Data Lake Storage Gen2. However, these input resources can live in the same Azure subscription as your Stream Analytics job or a different subscription.
Compression
Stream Analytics supports compression across all data stream input sources. Supported compression types are: None, GZip, and Deflate compression. Support for compression is not available for reference data.
Create, edit, or test inputs
You can use the Azure portal, Visual Studio, and Visual Studio Code to add and view or edit existing inputs on your streaming job. And, you can also test input connections and test queries from sample data. This can be done from the Azure portal, Visual Studio, and Visual Studio Code. However, when you write a query, you list the input in the FROM clause. You can get the list of available inputs from the Query page in the portal.
Stream data from Event Hubs
Azure Event Hubs provides highly scalable publish-subscribe event investors. An event hub can collect millions of events per second so that you can process and analyze the massive amounts of data produced by your connected devices and applications. Together, Event Hubs and Stream Analytics provide an end-to-end solution for real-time analytics. Moreover, Event Hubs lets you feed events into Azure in real-time, and Stream Analytics jobs can process those events in real-time.
Event Hubs Consumer groups
You should configure each Stream Analytics event hub input to have its own consumer group. When a job contains a self-join or has multiple inputs, some inputs might be read by more than one reader downstream. This situation impacts the number of readers in a single consumer group. Further, to avoid exceeding the Event Hubs limit of five readers per consumer group per partition, it’s a best practice to designate a consumer group for each Stream Analytics job. There is also a limit of 20 consumer groups for a Standard tier event hub.
Create an input from Event Hubs
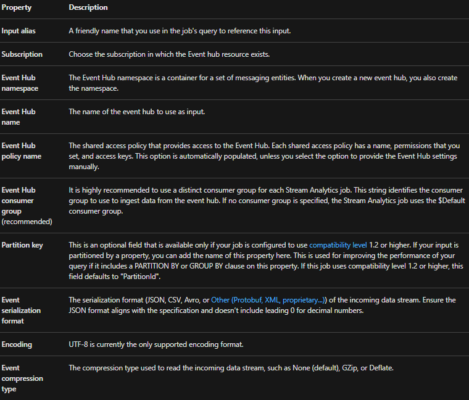
The following table explains each property in the New input page in the Azure portal to stream data input from an event hub:
Stream data from IoT Hub
Azure IoT Hub is a highly scalable publish-subscribe event ingestor optimized for IoT scenarios. And , the default timestamp of events coming from an IoT Hub in Stream Analytics is the timestamp that the event arrived in the IoT Hub, which is EventEnqueuedUtcTime. To process the data as a stream using a timestamp in the event payload, you must use the TIMESTAMP BY keyword.

Stream data from Blob storage or Data Lake Storage Gen2
- Firstly, for scenarios with large quantities of unstructured data to store in the cloud, Azure Blob storage or Azure Data Lake Storage Gen2 (ADLS Gen2) offers a cost-effective and scalable solution. Data in Blob storage or ADLS Gen2 is usually considered data at rest; however, this data can be processed as a data stream by Stream Analytics.
- Secondly, log processing is a commonly used scenario for using such inputs with Stream Analytics. In this scenario, telemetry data files have been captured from a system and need to be parsed and processed to extract meaningful data.
- Next, the default timestamp of a Blob storage or ADLS Gen2 event in Stream Analytics is the timestamp that it was last modified, which is BlobLastModifiedUtcTime.
- Next, if a blob is uploaded to a storage account container at 13:00. And, the Azure Stream Analytics job is started using Custom Time at 13:00 or earlier. Then, the blob will be picked up as its modified time falls inside the job run period.
- And, if an Azure Stream Analytics job is started using Now at 13:00, and a blob is uploaded to the storage account at 13:01. Then, Azure Stream Analytics will pick up the blob. The timestamp assigned to each blob is based only on BlobLastModifiedTime. The folder the blob is in has no relation to the the timestamp assigned.
- Further, to process the data as a stream using a timestamp in the event payload, you must use the TIMESTAMP BY keyword. A Stream Analytics job pulls data from Azure Blob storage or ADLS Gen2 input every second if the blob file is available. If the blob file is unavailable, there is an exponential backoff with a maximum time delay of 90 seconds.
Azure Stream Analytics output to Azure Cosmos DB
Azure Stream Analytics can target Azure Cosmos DB for JSON output, enabling data archiving and low-latency queries on unstructured JSON data. This document covers some best practices for implementing this configuration.
Basics of Azure Cosmos DB as an output target
The Azure Cosmos DB output in Stream Analytics enables writing your stream processing results as JSON output into your Azure Cosmos DB containers. Stream Analytics doesn’t create containers in your database. Instead, it requires you to create them up front. You can then control the billing costs of Azure Cosmos DB containers. You can also tune the performance, consistency, and capacity of your containers directly by using the Azure Cosmos DB APIs.
The following sections detail some of the container options for Azure Cosmos DB.
Tuning consistency, availability, and latency
To match your application requirements, Azure Cosmos DB allows you to fine-tune the database and containers and make trade-offs between consistency, availability, latency, and throughput. Further, depending on what levels of read consistency your scenario needs against read and write latency. There you can choose a consistency level on your database account. Also by default, Azure Cosmos DB enables synchronous indexing on each CRUD operation to your container. This is another useful option to control write/read performance in Azure Cosmos DB.
Upserts from Stream Analytics
Stream Analytics integration with Azure Cosmos DB allows you to insert or update records in your container based on a given Document ID column. This is also called an upsert. Any subsequent writes are handled as such, leading to one of these situations:
- Firstly, unique IDs lead to insert.
- Secondly, duplicate IDs and Document ID set to ID lead to upsert.
- Thirdly, duplicate IDs and Document ID not set lead to error, after the first document.
Data partitioning in Azure Cosmos DB
Azure Cosmos DB automatically scales partitions based on your workload. So we recommend unlimited containers as the approach for partitioning your data. When Stream Analytics writes to unlimited containers, it uses as many parallel writers as the previous query step or input partitioning scheme.
However, depending on your choice of partition key, you might receive this warning:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Further, it’s important to choose a partition key property that has a number of distinct values, and that lets you distribute your workload evenly across these values. As a natural artifact of partitioning, requests that involve the same partition key are limited by the maximum throughput of a single partition. Secondly, the storage size for documents that belong to the same partition key value is limited to 20 GB (the physical partition size limit is 50 GB). Partition keys used for Stream Analytics queries and Cosmos DB don’t need to be identical. Fully parallel topologies recommend using Input Partition key, PartitionId, as the Stream Analytics query’s partition key but that may not be the recommended choice for a Cosmos DB container’s partition key.
Azure Cosmos DB settings for JSON output
Using Azure Cosmos DB as an output in Stream Analytics generates the following prompt for information.
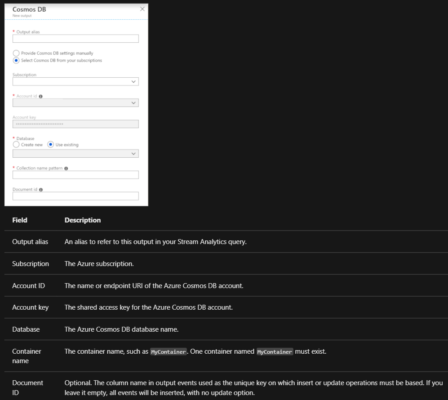
After you configure the Azure Cosmos DB output, you can use it in the query as the target of an INTO statement. When you’re using an Azure Cosmos DB output that way, a partition key needs to be set explicitly.
However, the output record must contain a case-sensitive column named after the partition key in Azure Cosmos DB. To achieve greater parallelization, the statement might require a PARTITION BY clause that uses the same column. Here’s a sample query:
SQL
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId

Reference: Microsoft Documentation, Documentation 2