AI Platform Pipelines Google Professional Data Engineer GCP
- makes it easier to get started with MLOps
- easily set up Kubeflow Pipelines with TensorFlow Extended (TFX).
- Kubeflow Pipelines is an open source platform for running, monitoring, auditing, and managing ML pipelines on Kubernetes.
- TFX is an open source project for building ML pipelines that orchestrate end-to-end ML workflows.
- ML pipelines are portable, scalable ML workflows
- Use ML pipelines to:
- Apply MLOps strategies to automate repeatable processes.
- Experiment by running an ML workflow with different sets of hyperparameters,
- Reuse a pipeline’s workflow to train a new model.
Pipeline Components
- are self-contained sets of code
- perform one step in a pipeline’s workflow like
- data preprocessing
- data transformation
- model training
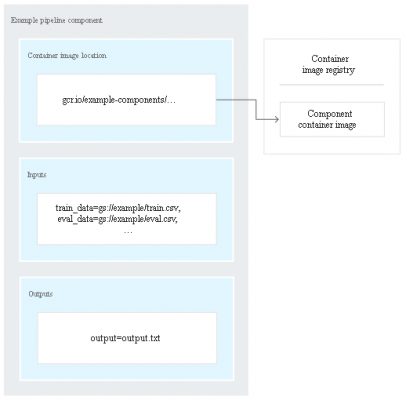
- composed of a
- set of input parameters
- set of outputs
- location of a container image
- A component’s container image includes
- component’s executable code
- definition of the environment that the code runs in.
Understanding pipeline workflow
- Each task in a pipeline performs a step in the pipeline’s workflow.
- tasks are instances of pipeline components,
- tasks have input parameters, outputs, and a container image.
- Task input parameters can be set from the pipeline’s input parameters
For example, consider a pipeline with the following tasks:
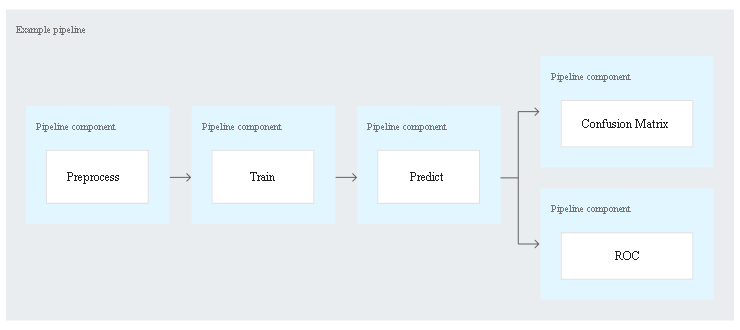 Preprocess: prepares the training data.
Preprocess: prepares the training data.- Train: uses the preprocessed training data to train the model.
- Predict: deploys trained model as an ML service and gets predictions for testing dataset.
- Confusion matrix: uses output of the prediction task to build a confusion matrix.
- ROC: uses the output of the prediction task to perform receiver operating characteristic (ROC) curve analysis.
Kubeflow Pipelines SDK analyzes the task dependencies, as
- The preprocessing task does not depend on any other tasks
- The training task relies on data produced by the preprocessing task, so training must occur after preprocessing.
- The prediction task relies on the trained model produced by the training task, so prediction must occur after training.
- Building the confusion matrix and performing ROC analysis both rely on the output of the prediction task, so they must occur after prediction is complete.
- Hence, system runs the preprocessing, training, and prediction tasks sequentially, and then runs the confusion matrix and ROC tasks concurrently.
- With AI Platform Pipelines, you can orchestrate machine learning (ML) workflows as reusable and reproducible pipelines.
Building pipelines using the TFX SDK
- TFX is an open source project to define ML workflow as a pipeline.
- TFX components can only train TensorFlow based models.
- TFX provides components to
- ingest and transform data
- train and evaluate a model
- deploy a trained model for inference, etc.
- By using the TFX SDK, you can compose a pipeline for ML process from TFX components.
Building pipelines using the Kubeflow Pipelines SDK
build components and pipelines by
- Developing the code for each step in workflow using preferred language and tools
- Creating a Docker container image for each step’s code
- Using Python to define pipeline using the Kubeflow Pipelines SDK